0. 引言
最近在做mysql到es的数据同步,涉及到父子表数据同步,特此记录,以供后续参考
关于mysql同步到es的操作明细可参考我之前的博客:
Elastic实战:通过canal1.1.5实现mysql8.0数据增量/全量同步到elasticsearch7.x
1.环境
canal 1.1.5
elasticsearch7.13
mysql 8.0
2. 基础类型数组同步
相关配置实际上在官方文档中都有示例,以下也是基于这些示例来实现的
这种方式针对的是数组中的数据为基础类型,比如List,List等
2.1 sql配置说明
sql支持多表关联自由组合, 但是有一定的限制:
1、主表不能为子查询语句
2、只能使用left outer join即最左表一定要是主表
3、关联从表如果是子查询不能有多张表
4、主sql中不能有where查询条件(从表子查询中可以有where条件但是不推荐, 可能会造成数据同步的不一致, 比如修改了where条件中的字段内容)
5、关联条件只允许主外键的’='操作不能出现其他常量判断比如: on a.role_id=b.id and b.statues=1
6、关联条件必须要有一个字段出现在主查询语句中比如: on a.role_id=b.id 其中的 a.role_id 或者 b.id 必须出现在主select语句中
7、Elastic Search的mapping 属性与sql的查询值将一一对应(不支持 select *), 比如: select a.id as _id, a.name, a.email as _email from user, 其中name将映射到es mapping的name field, _email将 映射到mapping的_email field, 这里以别名(如果有别名)作为最终的映射字段. 这里的_id可以填写到配置文件的 _id: _id映射
2.2 配置步骤
es mappings(已剔除部分字段)
{
"service_comment_driver" : {
"mappings" : {
"properties" : {
"id" : {
"type" : "keyword"
},
"avg" : {
"type" : "double"
},
"comment" : {
"type" : "text"
},
"createTime" : {
"type" : "date"
},
"labels" : {
"type" : "text",
"analyzer" : "ik_smart"
}
}
}
}
}
1、sql
将子表数据通过left join关联,并且将要查询的字段通过group_concat函数拼接起来,group_concat函数的作用是将group by产生的同一个分组中的值连接起来,返回一个字符串结果,并且不同行之间用separator指定的符号隔离
select
t.id as _id,
t.avg as avg,
t.create_time as createTime,
t.comment as comment,
l.labels
from
t_service_comment_driver t
left join
(select bussiness_id,group_concat(label order by id desc separator ';') as labels from t_service_comment_label
where type=0 group by bussiness_id) l
on
t.id = l.bussiness_id
2、adapter配置文件中添加配置
objFields:
labels: array:; # 数组属性, array:; 代表字段以;分隔的
整体的canal-adapter/conf/es7中的配置文件:comment.yml
dataSourceKey: duola_bussness # 这里的key与上述application.yml中配置的数据源保持一致
outerAdapterKey: esKey # 与上述application.yml中配置的outerAdapters.key一直
destination: example # 默认为example,与application.yml中配置的instance保持一致
groupId:
esMapping:
_index: service_comment_driver
_type: _doc
_id: _id
sql: "select
t.id as _id,
t.avg as avg,
t.create_time as createTime,
t.comment as comment,
l.labels
from
t_service_comment_driver t
left join
(select bussiness_id,group_concat(label order by id desc separator ';') as labels from t_service_comment_label
where type=0 group by bussiness_id) l
on t.id = l.bussiness_id"
objFields:
labels: array:; # 数组或者对象属性, array:; 代表以;字段里面是以;分隔的
#etlCondition: "where t.create_time>='{0}'"
commitBatch: 3000
3、启动adapter
./bin/startup.sh
4、修改对应的数据库表中的数据,然后查看日志
cat logs/adapter/adapter.log
发现已经有更新数据了

5、查看es中的数据
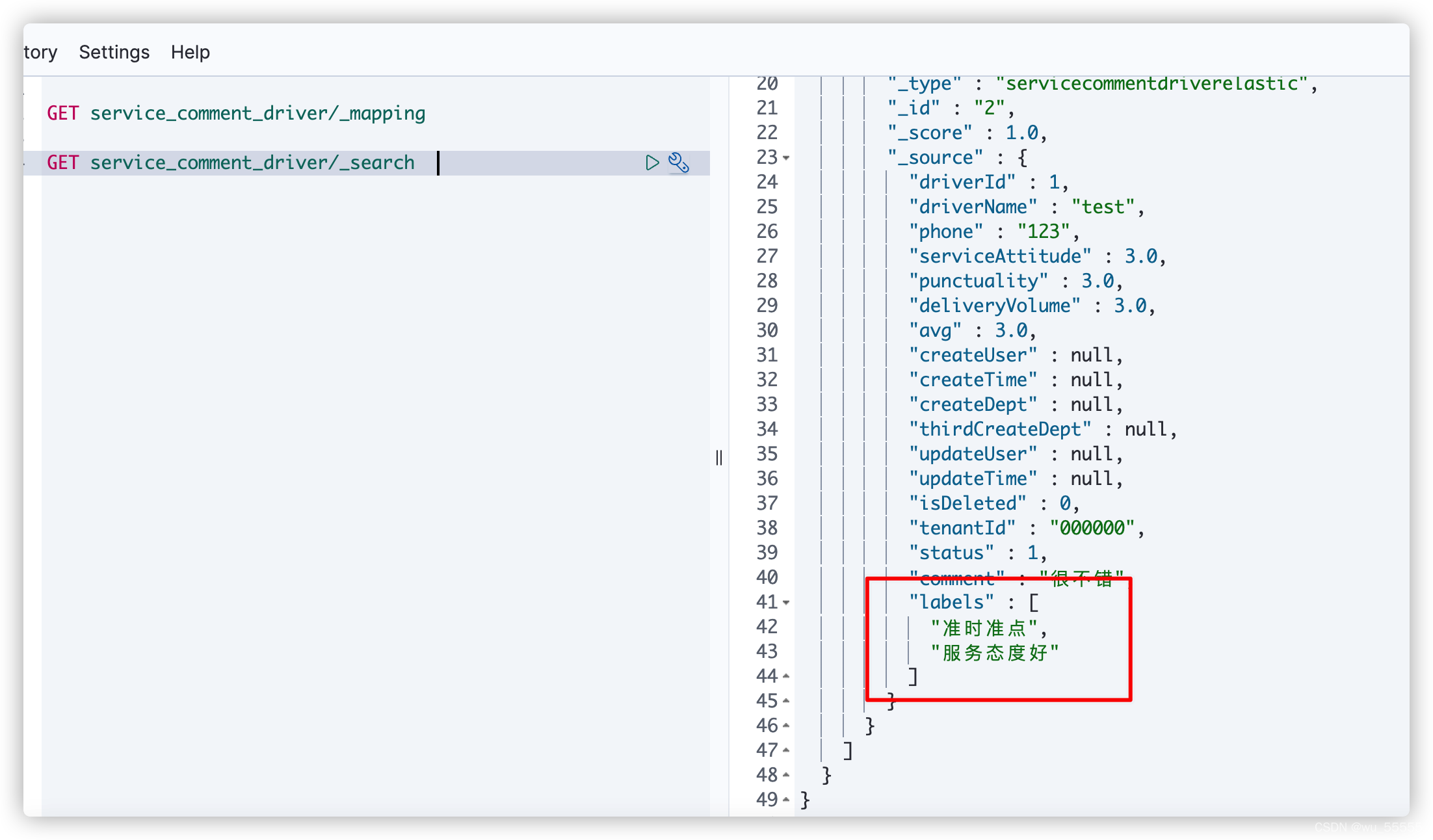
GET service_comment_driver/_search
发现labels中的数据已经同步更新了,并且是数组形式,修改子表数据后也会同步更新
2.3 常见报错
1. Unknown column ‘_v._id’ in ‘where clause’
将配置文件中的_id映射调整为_id即可,注意sql中的别名一样要为_id。
_id: _id
sql
select t.id as _id ...
3. 对象型数组同步
3.1 思路
这种方式针对的是数组中是自定义对象的数据,比如List<Object>
对比到es中的结构就是 List<Nested>
针对这一类型的同步,官方没有明确的示例说明能够支持,但是观察官方文档会发现官方提供了一个对象型字段的同步
objFields:
<field>: object
虽然官方的描述这一类型更针对的是一对一的json型字符串,但是不妨尝试一下,看看是否能够支持json型数组
canal中object是识别的json型字符串,所以我们的思路就是将子表数据转换为json字符串,然后通过object
3.2 配置步骤
1、es mapping
{
"service_comment_owner" : {
"mappings" : {
"properties" : {
"avg" : {
"type" : "double"
},
"comment" : {
"type" : "text"
},
"createTime" : {
"type" : "date"
},
"id" : {
"type" : "keyword"
},
"labels" : {
"type" : "nested",
"properties" : {
"id" : {
"type" : "long"
},
"label" : {
"type" : "text",
"analyzer" : "ik_smart"
},
"type" : {
"type" : "integer"
}
}
}
}
}
}
}
2、sql
select
t.id as _id,
t.avg as avg,
t.create_time as createTime,
t.comment as comment,
CONCAT('[',l.labels,']') as labels
from
t_service_comment_owner t
left join
(select bussiness_id,group_concat(json_object('id',id,'type',type,'label',label)) as labels from t_service_comment_label where type=1 group by bussiness_id) l
on
t.id=l.bussiness_id
3、adapter配置文件
objFields:
labels: object
4、整体配置文件
dataSourceKey: duola_bussness # 这里的key与上述application.yml中配置的数据源保持一致
outerAdapterKey: esKey # 与上述application.yml中配置的outerAdapters.key一直
destination: example # 默认为example,与application.yml中配置的instance保持一致
groupId:
esMapping:
_index: service_comment_owner
_type: _doc
_id: _id
sql: "select
t.id as _id,
t.avg as avg,
t.create_time as createTime,
t.comment as comment,
CONCAT('[',l.labels,']') as labels
from
t_service_comment_owner t
left join
(select bussiness_id,group_concat(json_object('id',id,'type',type,'label',label)) as labels from t_service_comment_label where type=1 group by bussiness_id) l
on
t.id=l.bussiness_id"
#etlCondition: "where t.update_time>='{0}'"
commitBatch: 3000
objFields:
labels: object # 数组或者对象属性
5、启动adapter
./bin/startup.sh
6、修改对应的数据库表中的数据,然后查看日志,会发现日志中有数据输出
cat logs/adapter/adapter.log
7、查询索引数据,注意因为是nested结构,所以使用nested查询
GET service_comment_owner/_search
{
"query": {
"nested": {
"path": "labels",
"query": {
"match": {
"labels.label": "信息"
}
}
}
}
}
会发现刚刚修改的信息已经更新上去了

3.3 常见报错
1. RuntimeException: com.alibaba.fastjson.JSONException: not close json text, token : ,
这个错误是因为json识别缺少必要符号导致的,因为我们上述的做法是将对象型数组转换为json数组,json数组需要在有[]符号,将这两个符号添加上就可以了
CONCAT('[',l.labels,']')
4. join型数据同步
4.1 join类型应用场景
所谓join型是指es中的join数据类型,这种类型适用于以下条件的场景
1、父子表结构的数据
2、子表数据明显多于父表数据
join类型不能像关系型数据库中的表连接那样去用,无论是has_child或者has_parent查询都会对索引的查询性能有严重的负面影响,并且会触发global ordinals。所以join类型不能遇到父子表结构就使用,先考虑上述两种方式,当子表数据远超父表数据时再考虑。
4.2 配置步骤
(因暂无应用需求,以下配置说明根据官方文档给出,后续持续更新)
1、es mappings
{
"mappings":{
"_doc":{
"properties":{
"id": {
"type": "long"
},
"name": {
"type": "text"
},
"email": {
"type": "text"
},
"order_id": {
"type": "long"
},
"order_serial": {
"type": "text"
},
"order_time": {
"type": "date"
},
"customer_order":{
"type":"join",
"relations":{
"customer":"order"
}
}
}
}
}
}
2、adapter/es7/customer.yml
esMapping:
_index: customer
_type: _doc
_id: id
relations:
customer_order:
name: customer
sql: "select t.id, t.name, t.email from customer t"
3、adapter/es7/order.yml配置文件
esMapping:
_index: customer
_type: _doc
_id: _id
relations:
customer_order:
name: order
parent: customer_id
sql: "select concat('oid_', t.id) as _id,
t.customer_id,
t.id as order_id,
t.serial_code as order_serial,
t.c_time as order_time
from biz_order t"
skips:
- customer_id
4、启动服务
./bin/startup.sh

原文地址:https://wu55555.blog.csdn.net/article/details/122643889

