0. 引言
我们知道在springboot单机架构中,可以使用@Transactional注解来快速的部署事务
但是在分布式架构下,@Transactional就无法发挥作用了。于是我们就需要一个能够支持分布式事务的组件来帮忙。于是乎,就引入了seata
1. 什么是分布式事务
在真正开始讲解seata之前,还是要给大家讲解清楚分布式事务。这样才能让大家真正体会到这个组件的作用。如果你已经掌握了这些概念,可以直接跳过这章。
1.1 什么是事务?
事务原本是用于单机架构,单数据库中的概念。表示要执行的一组操作,同时如果一组操作被申明为事务,那么就具备了四个特性:
- 原子性(Atomicity):一个事务中的所有操作,要么执行,要么都不执行。通过undo log实现(这里不再拓展什么是undo log,以及实现的细节,后续再单独说明)
- 一致性(Consistency):保证事务能把一个数据从一个正确的状态转移到另一个正确的状态,其中的中间状态是不会被其他事务所见的。通过锁机制实现(你有100W,我有10W,你打给我10W,对于你少了10W,我还没加上这10W的中间状态是不会被别的事务捕捉到的)
- 隔离性(Isolability):事务独立执行,不受其他并发操作影响;通过锁和MVCC来实现
- 持久性(Durability):事务完成后,对于数据的修改是永久的;通过redo log实现
事务中的一组操作,如果某一个操作发生报错,会通过undo log执行回滚,以此实现数据恢复成事务执行前的状态。
1.2 什么是分布式事务?
单机事务为什么不能使用在分布式系统?
如果不清楚这一点,建议大家实际体验一下。在服务A的方法中调用服务B的方法,让服务B的方法抛出一个错误,看看抛出错误后,服务A已经执行了的数据库操作会不会回退。
答案是不会的,因为他们根本不在一个事务中,我们可以在服务A中通过feign来调用服务B的方法,但是服务B的方法并不归属于服务A的事务体系中,因此服务B的报错并不会导致已经执行了的服务A的操作回退。
想要让服务A回退,那么就要让服务B纳入到服务A的事务体系中,也就是两者是同一个事务ID。这就是我们的分布式事务,它可以跨越服务来实现事务。
我在知乎上看到一个有意思的比喻:普通事务是小汽车倒车入库,要么成功,要么退出了重新倒。而分布式事务,是火车倒车入站,必须每一节都成功,不然就要一节一节的退出去重新来。
我们从物理概念上来理解,分布式事务是跨服务的,甚至是跨服务器的。
想要实现分布式事务,我们有多种方式,可以通过像redis这样的中间件来实现。但也可以用到我们今天介绍的seata组件来实现。甚至发展至今,一般我们谈到分布式事务,基本上seata已经成了我们的不二选择。
2. seata介绍
seata是一款由阿里巴巴开源的分布式事务组件。提供了AT、TCC、SAGA和XA等几种事务模式
seata官方开发文档。我们默认使用的是AT模式。
关于各种模式的工作原理,这里不做拓展了,先教会大家如何使用,后续我们再来详谈原理。感兴趣的同学也可以参考官方开发文档中的说明
2.1 AT模式工作机制
1、seata首先要求在业务表所在的数据库中创建一个undo_log表,用于记录回滚sql。所谓回滚sql就是与所执行sql相反的sql,比如执行了一个insert语句,那么对应的undo log就是一条delete语句。
2、业务表执行了操作后,seata会将执行的sql进行解析,生成回滚sql并且存储到undo_log表中
3、本地事务提交前,会向seata的服务端注册分支,申请对应的业务表中对应数据行的全局锁,这时其他的事务就无法对这条数据进行更新操作。
4、本地事务提交,业务数据的更新和前面生成的undo log会一起提交
5、将本地事务的执行结果上报给seata服务端。也就是说seata服务端会记录多个服务的本地事务。同时这些本地事务因为在seata服务端的管控之下,所以使用的事务ID和分支ID都是一样的。
6、如果某一个本地事务发生报错,那么seata服务端就会发起对应分支的回滚请求
7、同时开启一个本地事务,然后通过事务ID和分支ID去undo_log表查询到对应的回滚sql。并且执行回滚sql,再将执行结果上报给seata服务端
8、如果没有发生报错,seata服务端也会在对应分支发起请求,然后会异步批量的删除undo_log表中的记录
总结一句话,为什么能实现分布式事务,就是因为seata服务端将这些本地事务都记录下来了,同时也在每个库中记录了undo log。当有一个报错时,就找到这同一组的所有的本地事务,然后统一利用记录的undo log回退数据
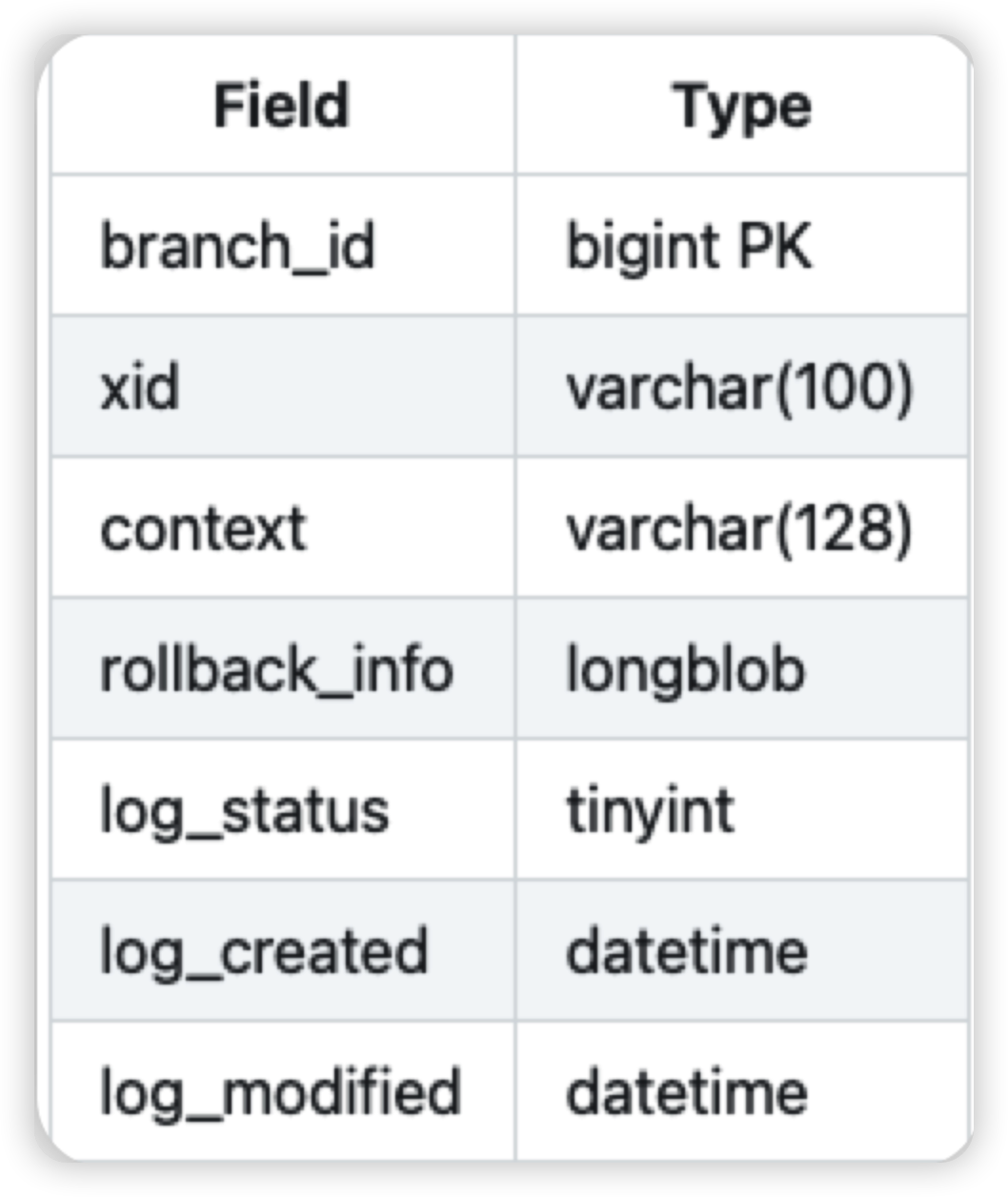
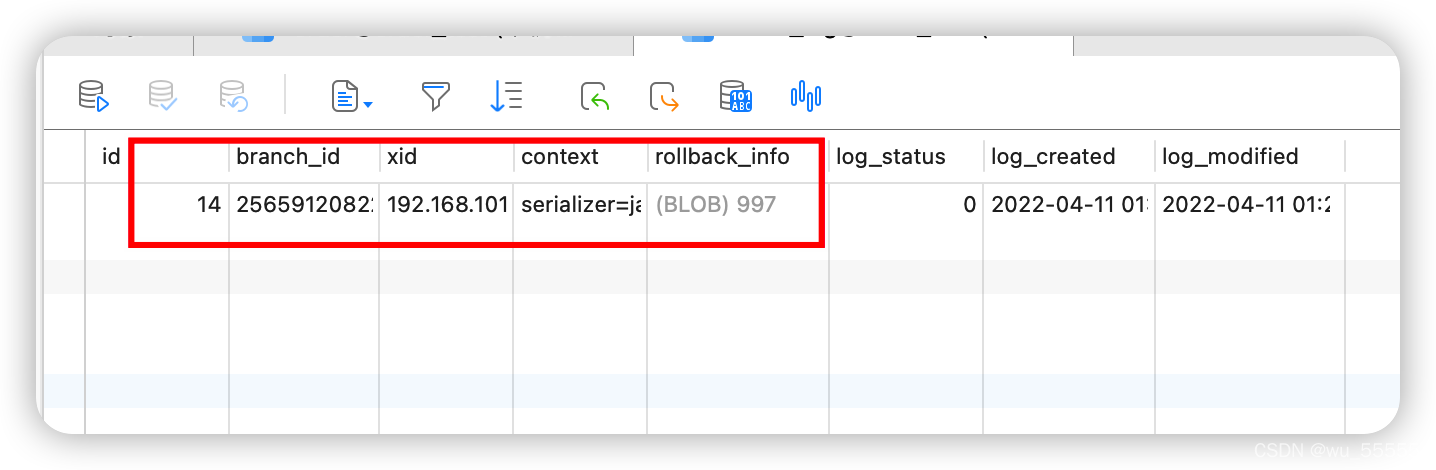
大家可以看看mysql undo log表涉及的字段。其中xid就是事务ID,branch_id就是分支ID
3. seata使用
seata分为服务端(TC)和客户端(TM,RM),客户端通过引入jar包来使用。而服务端就需要我们单独安装了。
- TC(Transaction Coordinator):事务协调器,维护全局事务的运行状态,协调和落实全局事务的回滚提交
-TM(Transaction Manager):控制全局事务的边界,负责开启一个全局事务,并最终发起全局事务提交或回滚的决议 - RM(Resource Manager):控制分支(本地)事务,负责分支注册、状态汇报,并接受TC的指令,驱动本地事务的提交和回滚
seata中涉及到配置中心和注册中心的设置。seata支持的注册中心有:
- eureka
- consul
- nacos
- etcd
- zookeeper
- sofa
- redis
- file(文件形式,直连)
支持的配置中心有:
- nacos
- consul
- apollo
- etcd
- zookeeper
- file(本地文件,包含conf,properties,yml配置文件的支持)
为了配置之前学习的知识体系(如不知道的,可查看专栏之前的博客),我们使用nacos作为注册中心,采用file作为配置中心,这里不用nacos作为配置中心,是因为目前seata对于nacos配置中心的配置比较复杂,不太适合初步学习。所以我们采用file形式。
如想使用其他组件作为注册中心、配置中心可参考官方文档
3.1 下载seata服务端
这里我们以seata1.4.0版本为例,官方建议安装1.4.0+版本
3.2 安装seata服务端
1、解压安装包
tar -zxvf seata-server-1.4.0.tar.gz
2、修改配置文件registry.conf,seata安装目录下执行
vim conf/registry.conf
修改内容
registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "nacos"
loadBalance = "RandomLoadBalance"
loadBalanceVirtualNodes = 10
nacos {
application = "seata-server"
serverAddr = "127.0.0.1:8848"
group = "SEATA_GROUP"
namespace = ""
cluster = "default"
username = "nacos"
password = "nacos"
}
}
配置中心采用默认的file形式,因此无需修改,使用默认的即可
config {
# file、nacos 、apollo、zk、consul、etcd3
type = "file"
file {
name = "file.conf"
}
}
3、修改file.conf配置文件,配置持久化方式。默认采用的file形式,更建议使用db形式。这里以mysql举例
vim conf/file.conf
修改内容
store {
## store mode: file、db、redis
mode = "db"
## database store property
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp)/HikariDataSource(hikari) etc.
datasource = "druid"
## mysql/oracle/postgresql/h2/oceanbase etc.
dbType = "mysql"
driverClassName = "com.mysql.jdbc.Driver"
url = "jdbc:mysql://127.0.0.1:3306/seata"
user = "mysql"
password = "mysql"
minConn = 5
maxConn = 100
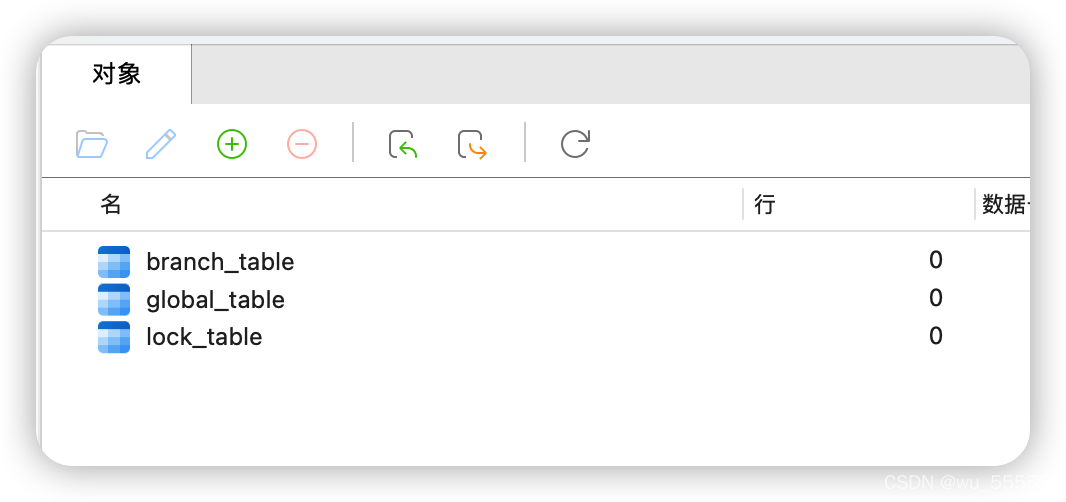
globalTable = "global_table"
branchTable = "branch_table"
lockTable = "lock_table"
queryLimit = 100
maxWait = 5000
}
}
4、导入seata数据库
创建seata数据库
导入表结构:表结构sql文件下载地址
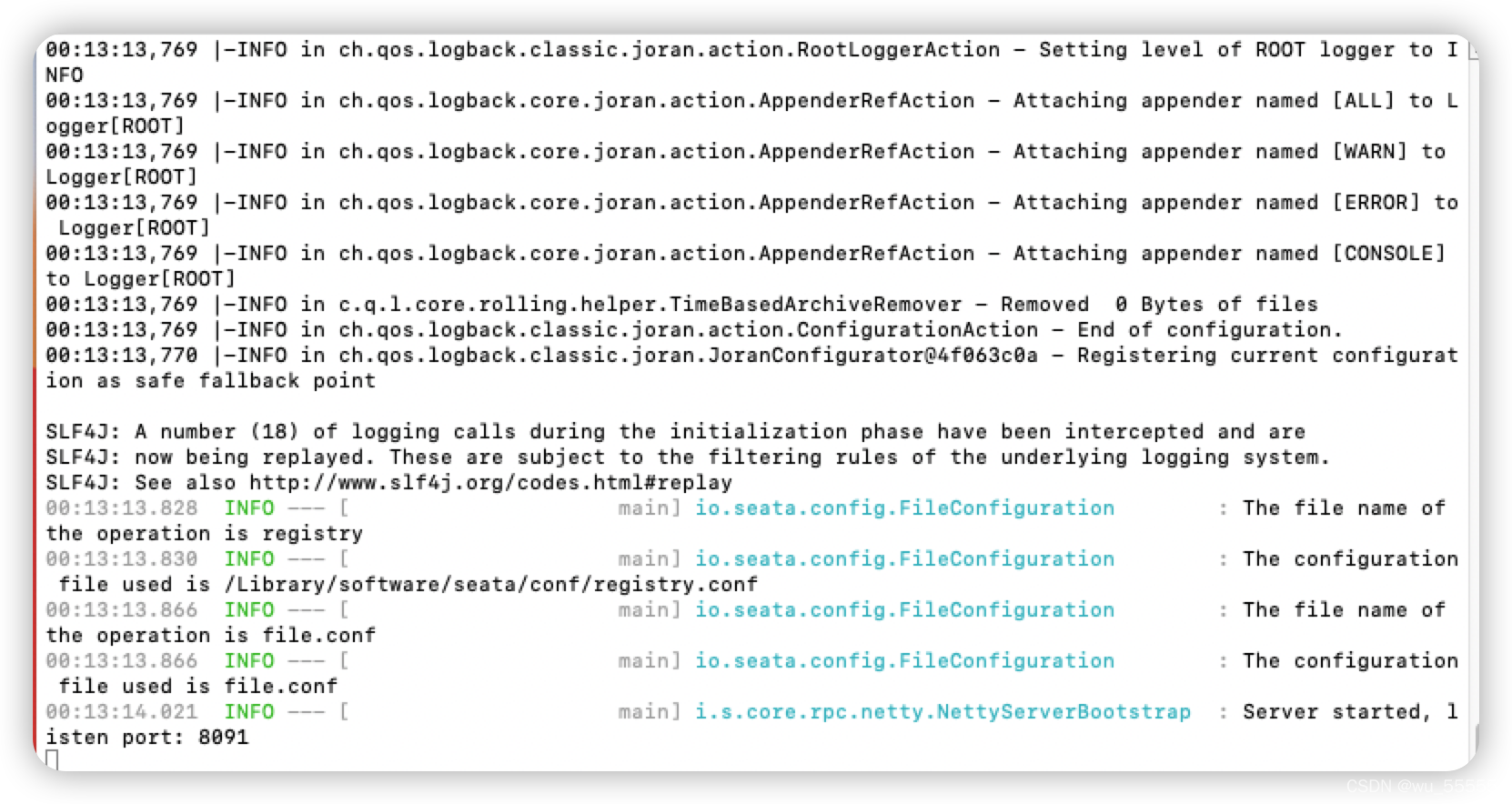
5、启动seata-server。seata-server端口是8091,如果是安装在虚拟机上的,记得打开8091端口
./bin/seata-server.sh
3.3 seata客户端配置
这里我们结合之前搭建的微服务框架来演示客户端的配置,不知道的可以参考之前的博客
springcloud:保姆式教程-从零搭建微服务
3.3.1 准备工作
该项目的springcloud2中有两个微服务:订单服务和商品服务
1、在两个服务中引入依赖,与服务端保持版本
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>1.4.0</version>
</dependency>
<dependency>
<groupId>com.alibaba.nacos</groupId>
<artifactId>nacos-client</artifactId>
<version>1.4.0</version>
</dependency>
2、在两个服务的配置文件中添加如下配置。
注意:
(1)这里的group要与server端配置的保持一致
(2)seata.service.vgroupMapping.xxx中的xxx为事务群组,要部署同一套分布式事务的微服务要求事务群组要一致。其值是在server 端conf/registry.conf配置的nacos集群名称registry.nacos.cluster
seata:
tx-service-group: my-seata-service-group
registry:
type: nacos
nacos:
application: seata-server
server-addr: 127.0.0.1:8848
group : "SEATA_GROUP"
namespace: ""
username: "nacos"
password: "nacos"
service:
vgroupMapping:
# 事务群组,其值为seata server端配置的seata集群名,与registry.nacos.cluster保持一致,默认是default
my-seata-service-group: default
客户端完整配置文件见官方github地址
3、在客户端涉及到的业务数据库中添加undo_log表
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
3.3.2 测试
1、在product-server中添加保存接口
这里1/0会抛出错误,我们来模拟报错后数据回退
@PostMapping("save")
public String save(){
Product product = new Product();
product.setId(555L);
product.setName("商品xxx");
product.setPrice(300.0);
product.setNo("SP001");
product.setCreateTime(new Date());
int i = 1/0;
return productService.save(product) ? "保存成功" : "保存失败";
}
2、在order-server feign中创建调用product-server save接口
@FeignClient(name = "product-server",url = "localhost:9091")
public interface ProductApi {
@GetMapping("list")
public List<Product> list();
@PostMapping("save")
public String save();
}
3、在order-server中添加保存接口:保存订单的同时,调用product-server的save接口保存商品
在调用方接口中添加@GlobalTransactional注解
@GlobalTransactional
@PostMapping("save")
public String save(){
Order order = new Order();
order.setId(555L);
order.setOrderNo("DD001");
order.setCreateTime(new Date());
orderService.save(order);
return productApi.save();
}
4、运行项目,调用order-server save接口
3.3.3 结果分析
1、我们在product-server的save方法执行前打个断点
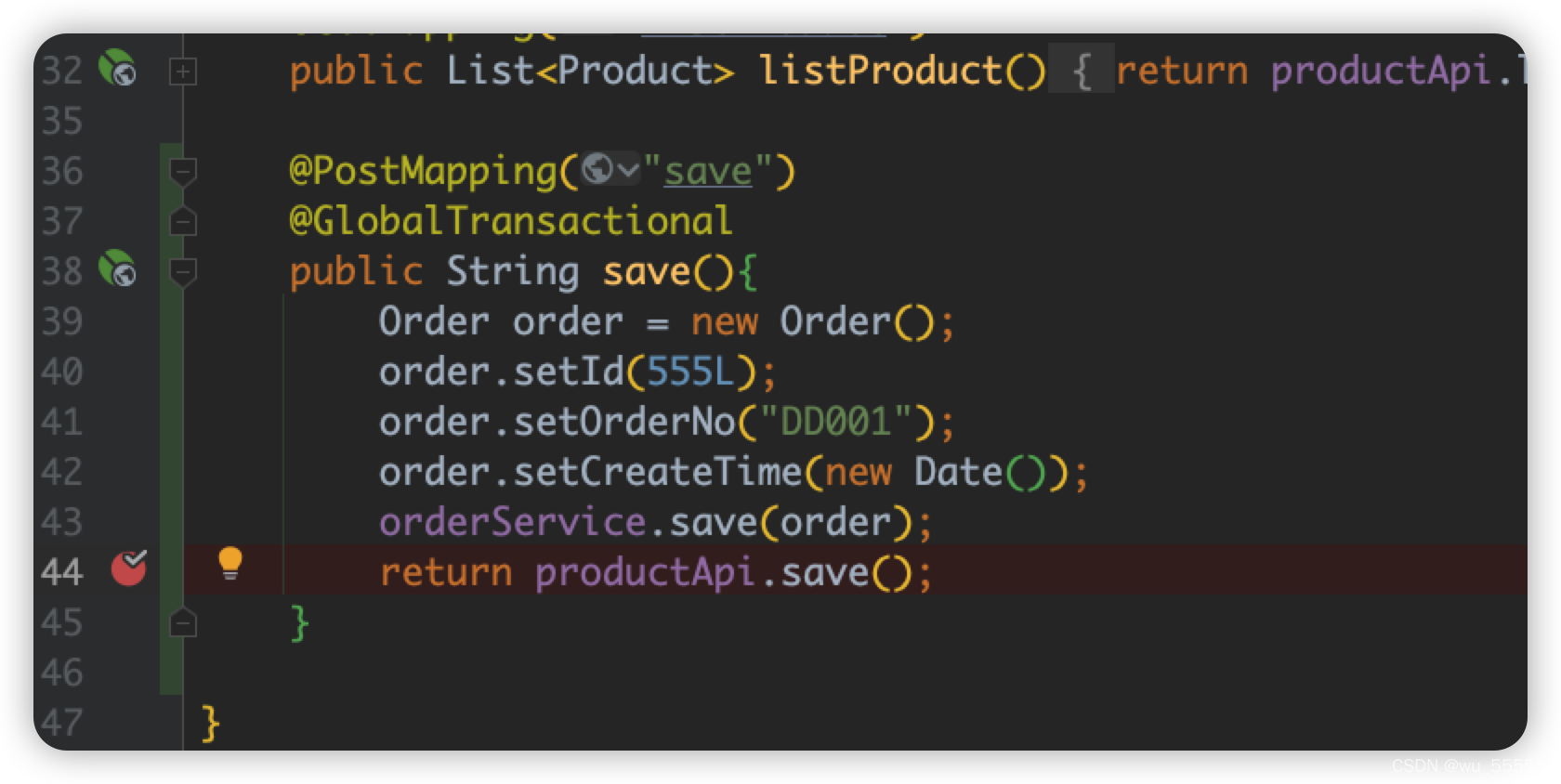
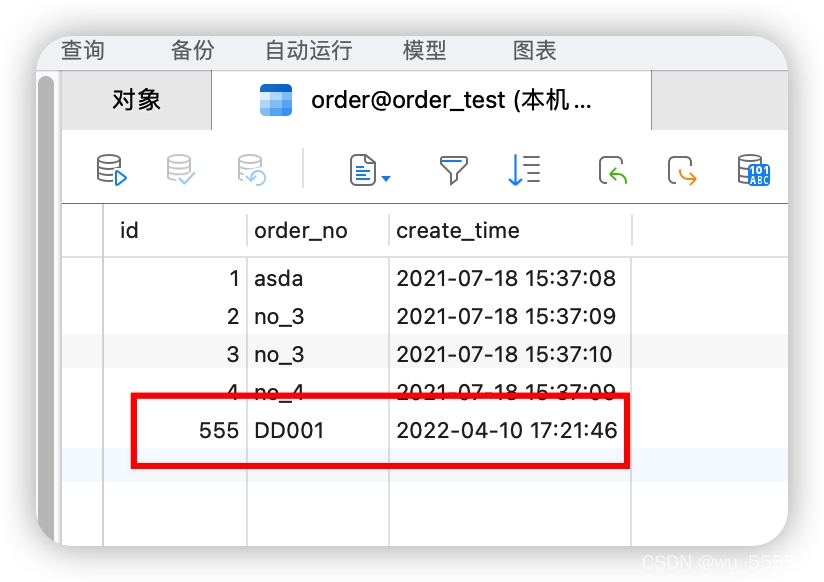
2、然后观察order表,发现新增的订单数据已经添加成功
3、同时观察undo_log表,发现已经产生了一条数据
4、我们让代码继续执行,抛出错误

5、同时我们再观察order表,发现数据成功回退了

6、看看undo_log中的记录,因为回退执行完后也已经删除了。
7、那么到这里我们的分布式事务就部署成功了。
3.4 注意事项
1、只需要在调用方添加一个@GlobalTransactional注解即可,无需在被调用方添加@Transactional注解
2、客户端中的seata.tx-service-group和seata.service.vgroupMapping.xxx配置不要忘记,且同事务组保持统一
4. 其他API
- 获取分布式事务ID
RootContext.getXID()
- 指定事务手动回滚
TransactionManagerHolder.get().rollback(RootContext.getXID());
- 当前事务手动回滚
// 1. 获取当前全局事务实例或创建新的实例
GlobalTransaction tx = GlobalTransactionContext.getCurrentOrCreate();
tx.rollback();
更多API介绍可见官方文档
5. 常见报错
can not get cluster name in registry config
报错:
i.s.c.r.netty.NettyClientChannelManager : can not get cluster name in registry config 'service.vgroupMapping.order-server-seata-service-group', please make sure registry config correct
解决:
在微服务中添加配置
seata:
tx-service-group: my-seata-service-group
service:
vgroupMapping:
# 事务群组,其值为seata server端配置的seata集群名,与registry.nacos.cluster保持一致,默认是default
my-seata-service-group: default
项目源码地址
关注公众号,了解更多新鲜内容

原文地址:https://wu55555.blog.csdn.net/article/details/124083075

