1、单个索引的字段数量上限
参数:index.mapping.total_fields.limit
阈值:1000
解释:索引中的最大字段数。字段和对象映射以及字段别名计入此限制。默认值为1000。
此限制是为了防止映射和搜索变得过大。较高的值会导致性能下降和内存问题,尤其是在负载高或资源少的集群中。
2、映射字段最大嵌套深度
参数:index.mapping.depth.limit
阈值:20
解释:场的最大深度,以内部对象的数量来衡量。例如,如果所有字段都在根对象级别定义,则深度为1. 如果有一个对象映射,则深度为 2等。默认为20。
3、字段名称最大长度
参数:index.mapping.field_name_length.limit
阈值:无限制
解释:设置字段名称的最大长度。此设置并不是真正解决映射爆炸的问题,但如果需要限制字段长度,它可能仍然有用。通常不需要设置此设置。除非用户开始添加大量名称很长的字段,否则默认值是可以的。默认为 Long.MAX_VALUE(无限制)。
4、分页查询最大文档查询数量
参数:index.max_result_window
阈值:10000
解释:max_result_window是查询的最大数值,默认值为10000。也就是当 from + size 大于10000的时候,就会出现问题,如下图报错信息所示:
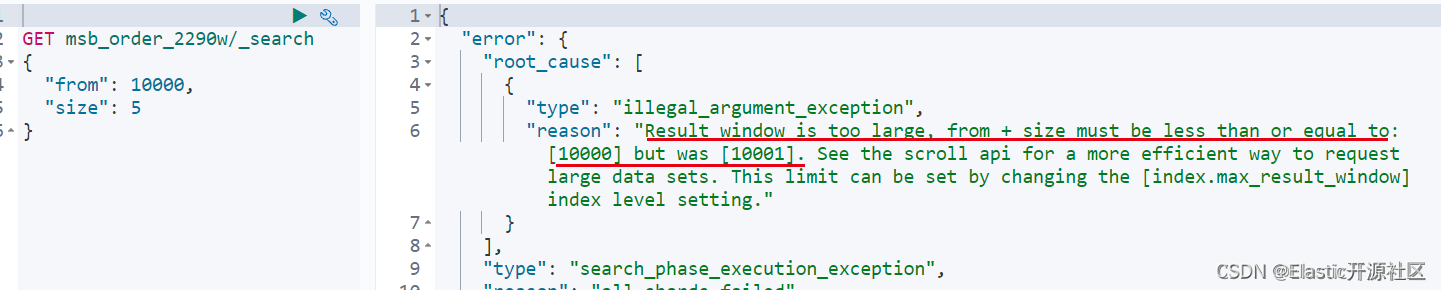
max_result_window本身是对JVM的一种保护机制,通过设定一个合理的阈值,避免初学者分页查询时由于单页数据过大而导致OOM。
在很多业务场景中经常需要查询10000条以后的数据,当遇到不能查询10000条以后的数据的问题之后,网上的很多答案会告诉你可以通过放开这个参数的限制,将其配置为100万,甚至1000万就行。但是如果仅仅放开这个参数就行,那么这个参数限制的意义有何在呢?如果你不知道这个参数的意义,很可能导致的后果就是频繁的发生OOM而且很难找到原因,设置一个合理的大小是需要通过你的各项指标参数来衡量确定的,比如你用户量、数据量、物理内存的大小、分片的数量等等。通过监控数据和分析各项指标从而确定一个最佳值,并非越大约好。
5、文档查询的最大召回数量
参数:track_total_hits
阈值:10000
解释:匹配查询准确计数的命中数。默认为10000
如果设置为 track_total_hits: true ,则以牺牲一些性能为代价返回准确的命中数。回参hits里面的total才是真实业务的总条数,不然的话Elasticsearch 限制了最多的数值为10000(10000以内没问题,超出10000就看不出来了)如果false,则响应不包括与查询匹配的总命中数。
6、组合查询(bool query)最大字句限制
参数:indices.query.bool.max_clause_count
阈值:1024
解释:匹配查询准确计数的命中数。默认为10000
此设置限制 Lucene Boolean Query 可以拥有的子句数量。默认值 1024 相当高,通常应该足够了。此限制不仅影响 Elasticsearch bool查询,而且许多其他查询在内部被重写为 Lucene 的 BooleanQuery。该限制是为了防止搜索变得过大并占用过多的 CPU 和内存。除非用尽办法已无其他优化手段而不得不这样做,否则不要增加这个值。较高的值会导致性能急剧下降和内存问题,尤其是在负载高或资源少的集群中。
7、聚合查询最大分桶数量
参数:search.max_buckets
阈值:65,536
解释:尝试返回超过此限制的请求将返回错误。
8、单次查询最大词项数量
参数:max_query_terms
阈值:25
解释:最大查询词数,默认为 25。增加此值会以牺牲查询执行速度为代价提供更高的准确性。
9、单个分片最大文档数量上限(shard max doc count)
阈值:2^31-1 或者 2147483647
10、单个文档最大容量上限
参数:http.max_content_length
阈值:
- ES阈值:100MB
- Lucene阈值:2GB
解释:大文档对网络、内存使用和磁盘造成很大压力,即便查询的时候不请求源数据"_source"也是一样。因为 Elasticsearch 在所有情况下都需要获取文档的 _id。对该文档进行索引可能会占用文档原始大小的倍数的内存量。邻近搜索(例如短语查询)和突出显示也变得更加昂贵,因为它们的成本直接取决于原始文档的大小


