知识内容输出不易,请尊重他人劳动成果。严禁随意传播、复制和盗用他人成果或文章内容用以商业或盈利目的!
1、分词器认知基础
1.1 基本概念
分词器官方称之为文本分析器,顾名思义,是对文本进行分析处理的一种手段,基本处理逻辑为按照预先制定的分词规则,把原始文档分割成若干更小粒度的词项,粒度大小取决于分词器规则。
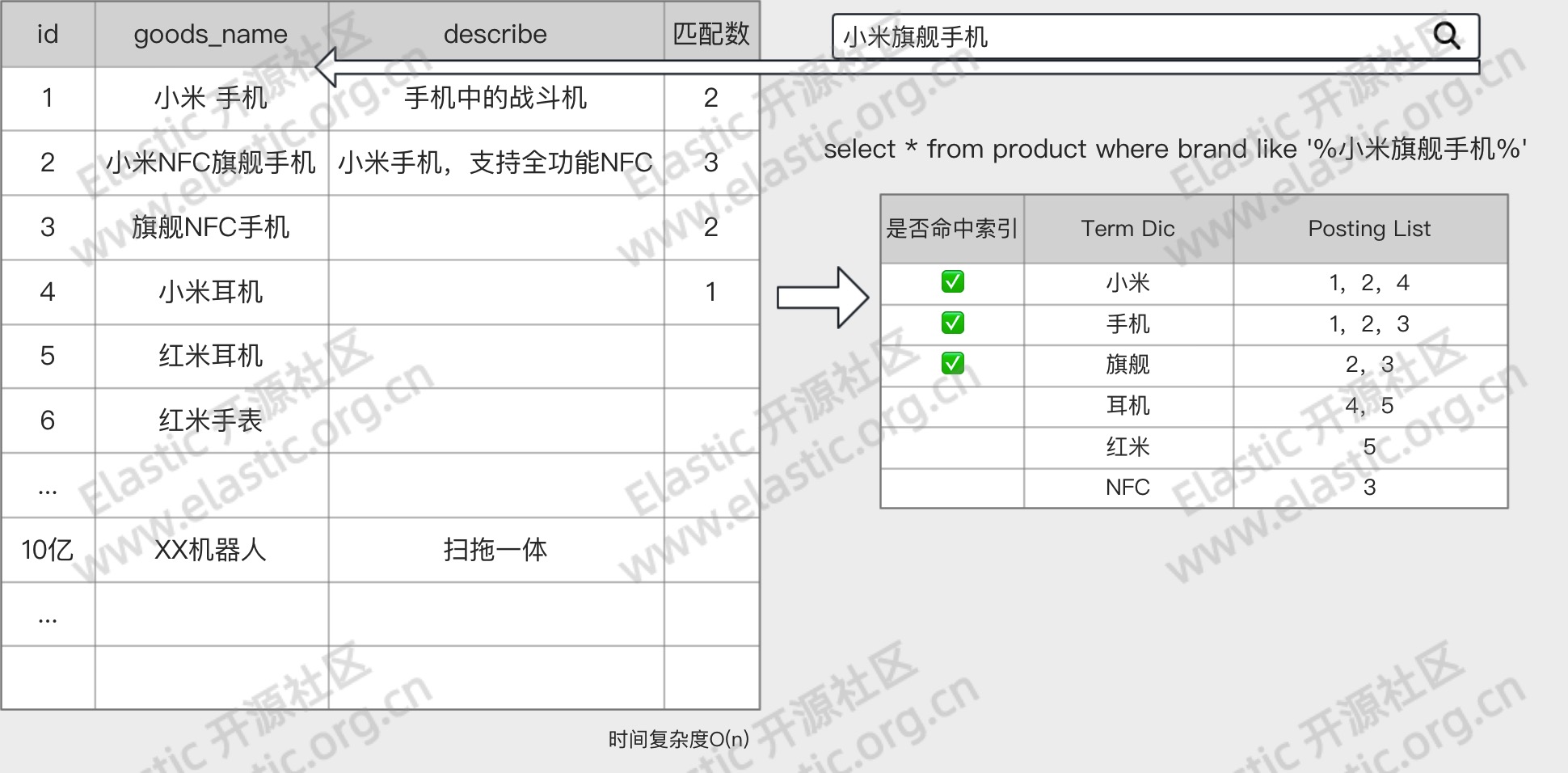
1.2 分词发生时期
分词器的处理过程发生在 Index Time 和 Search Time 两个时期。
- Index Time:文档写入并创建倒排索引时期,其分词逻辑取决于映射参数
analyzer。 - Search Time:搜索发生时期,其分词仅对搜索词产生作用。
1.3 分词器的组成
- 切词器(Tokenizer):用于定义切词(分词)逻辑
- 词项过滤器(Token Filter):用于对分词之后的单个词项的处理逻辑
- 字符过滤器(Character Filter):用于处理单个字符
注意:
- 分词器不会对源数据造成任何影响,分词仅仅是对倒排索引或者搜索词的行为。
2、文档归一化处理:Normalization
2.1 Processors
- 大小写统一
- 时态转换
- 停用词:如一些语气词、介词等在大多数场景下均无搜索意义
注意:文档归一化处理的场景不仅限于以上几点,具体取决于分词器如何定义。
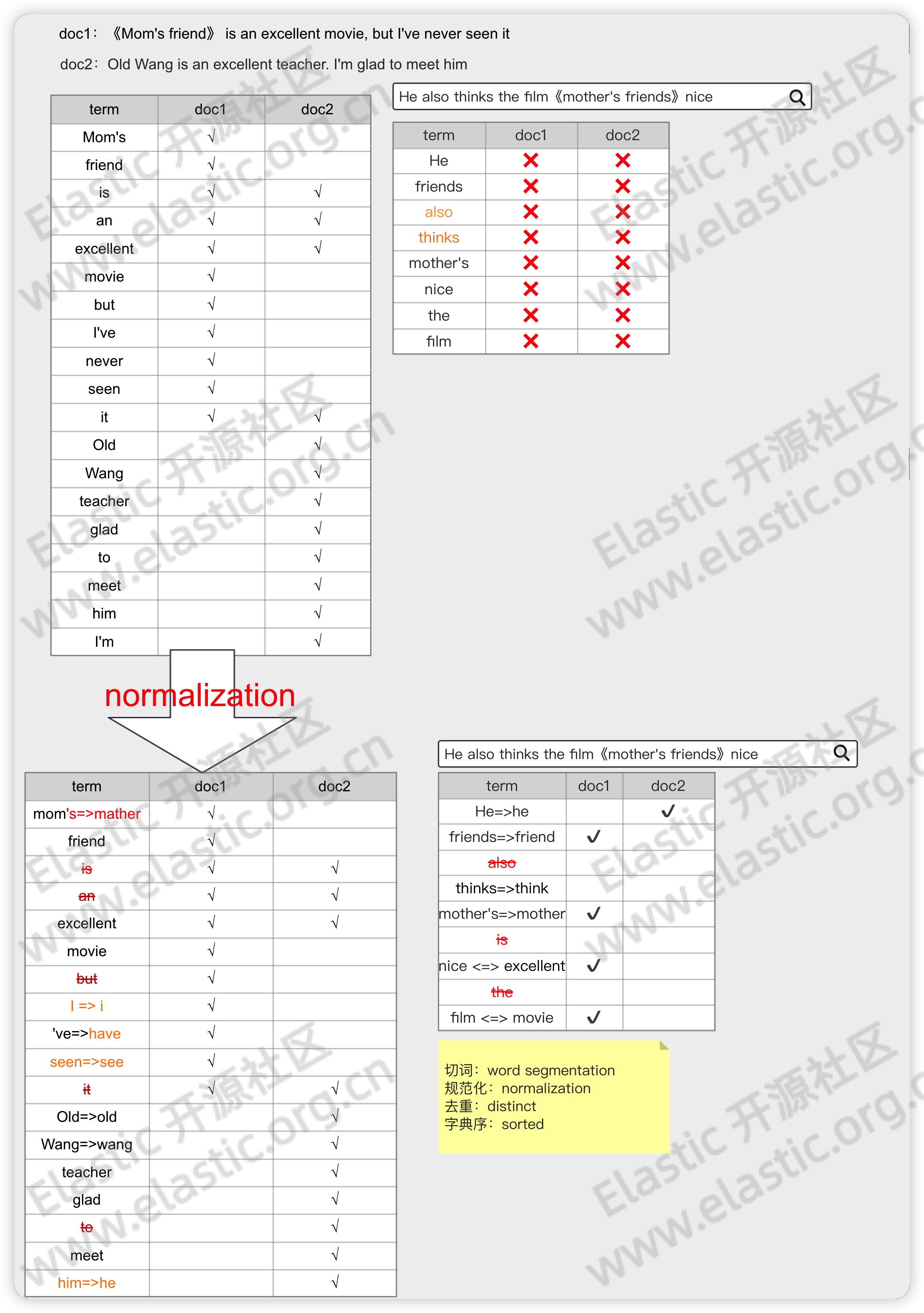
2.2 意义
- 增加召回率
- 减小匹配次数,进而提高查询性能
2.3 _analyzer API
_analyzer API可以用来查看指定分词器的分词结果。
语法如下:
GET _analyze
{
"text": ["What are you doing!"],
"analyzer": "english"
}
3、切词器:Tokenizer
tokenizer 是分词器的核心组成部分之一,其主要作用是分词,或称之为切词。主要用来对原始文本进行细粒度拆分。拆分之后的每一个部分称之为一个 Term,或称之为一个词项。
可以把切词器理解为预定义的切词规则。
官方内置了很多种切词器,默认的切词器位 standard。
4、词项过滤器:Token Filter
4.1 简介
词项过滤器用来处理切词完成之后的词项,例如把大小写转换,删除停用词或同义词处理等。
官方同样预置了很多词项过滤器,基本可以满足日常开发的需要。当然也是支持第三方也自行开发的。
4.2 案例
下面将通过案例演示不同词项过滤器的基本使用。
4.2.1 Lowercase 和 Uppercase
GET _analyze
{
"filter" : ["lowercase"],
"text" : "WWW ELASTIC ORG CN"
}
GET _analyze
{
"tokenizer" : "standard",
"filter" : ["uppercase"],
"text" : ["www.elastic.org.cn","www elastic org cn"]
}
4.2.2 停用词
在切词完成之后,会被干掉词项,即停用词。停用词可以自定义
英文停用词(english):a, an, and, are, as, at, be, but, by, for, if, in, into, is, it, no, not, of, on, or, such, that, the, their, then, there, these, they, this, to, was, will, with。
中日韩停用词(cjk):a, and, are, as, at, be, but, by, for, if, in, into, is, it, no, not, of, on, or, s, such, t, that, the, their, then, there, these, they, this, to, was, will, with, www
GET _analyze
{
"tokenizer": "standard",
"filter": ["stop"],
"text": ["What are you doing"]
}
### 自定义 filter
DELETE test_token_filter_stop
PUT test_token_filter_stop
{
"settings": {
"analysis": {
"filter": {
"my_filter": {
"type": "stop",
"stopwords": [
"www"
],
"ignore_case": true
}
}
}
}
}
GET test_token_filter_stop/_analyze
{
"tokenizer": "standard",
"filter": ["my_filter"],
"text": ["What www WWW are you doing"]
}
4.2.3 同义词
同义词定义规则
- a, b, c => d:这种方式,a、b、c 会被 d 代替。
- a, b, c, d:这种方式下,a、b、c、d 是等价的。
同义词定义方式
- 内联:直接在
synonym内部声明规则 - 文件:在文件中定义规则,文件相对顶级目录为 ES 的 Config 文件夹。
代码
PUT test_token_filter_synonym
{
"settings": {
"analysis": {
"filter": {
"my_synonym": {
"type": "synonym",
"synonyms": [ "good, nice => excellent" ] //good, nice, excellent
}
}
}
}
}
GET test_token_filter_synonym/_analyze
{
"tokenizer": "standard",
"filter": ["my_synonym"],
"text": ["good"]
}
DELETE test_token_filter_synonym
PUT test_token_filter_synonym
{
"settings": {
"analysis": {
"filter": {
"my_synonym": {
"type": "synonym",
"synonyms_path": "analysis/synonym.txt"
}
}
}
}
}
GET test_token_filter_synonym/_analyze
{
"tokenizer": "standard",
"text": ["a"], // a b c d s; q w e r ss
"filter": ["my_synonym"]
}
5、字符过滤器:Character Filter
5.1 基本概念
分词之前的预处理,过滤无用字符
5.2 基本用法
5.2.1 ****
PUT <index_name>
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter": {
"type": "<char_filter_type>"
}
}
}
}
}
5.2.2 ****
-
type:************************,************
- html_strip
- mapping
- pattern_replace
5.3 ************** Char Filter
5.3.1 HTML **********:HTML Strip Character Filter
**************** HTML ********** HTML ****,** 、&
PUT PUT test_char_filter
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter": {
"type": "html_strip", // html_strip ******** HTML **********
"escaped_tags": [ // ********** a ****
"a"
]
}
}
}
}
}
GET test_html_strip_filter/_analyze
{
"tokenizer": "standard",
"char_filter": ["my_char_filter"],
"text": ["<p>I'm so <a>happy</a>!</p>"]
}
****:
- escaped_tags:********** html ****
5.3.2 **************:Mapping Character Filter
********************,************************
PUT test_html_strip_filter
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter": {
"type": "mapping", // mapping **********************
"mappings": [ // ****************************** => **********
"** => *",
"** => *",
"** => *"
]
}
}
}
}
}
GET test_html_strip_filter/_analyze
{
//"tokenizer": "standard",
"char_filter": ["my_char_filter"],
"text": "************!**"
}
5.3.3 **************:Pattern Replace Character Filter
PUT text_pattern_replace_filter
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter": {
"type": "pattern_replace", // pattern_replace **********************
"pattern": """(\d{3})\d{4}(\d{4})""", // **********
"replacement": "$1****$2"
}
}
}
}
}
GET text_pattern_replace_filter/_analyze
{
"char_filter": ["my_char_filter"],
"text": "************18868686688"
}
6、**********:
- Standard ★:**********,****************,**********。********:standard
- Pattern:****************,********************。********:pattern
- Simple:******************,**************,********:simple
- Whitespace ★:************,**************,********:whitespace
- Keyword ★:******************************,************************,********:keyword
- Stop:********** Simple Analyzer ****,************************。********:stop
- Language Analyzer:************************。
- Fingerprint:******************,******
7、************:Custom Analyzer
7.1 **********************
**** ES **********************,****************、**********、******************************************。****************************************:
- Tokenizer:**********************************,**************************。
- Token Filter:********************,************************
- Char Filter:********************,************************
7.2 type ****
PUT <index_name>
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": { // ****************
"type": "<value>", // **** ES **********,************ custom ****************
...
}
}
}
}
}
- type:********** 6 ****************,**********
custom**************
7.3 ****
PUT test_analyzer
{
"settings": {
"analysis": {
"tokenizer": {
"my_tokenizer": {
"type": "pattern",
"pattern": "[ ,.!?]"
}
},
"char_filter": {
"html_strip_char_filter": {
"type": "html_strip",
"escaped_tags": [
"a"
]
},
"my_char_filter": {
"type": "mapping",
"mappings": [
"** => *",
"** => *",
"** => *"
]
}
},
"filter": {
"my_filter": {
"type": "stop",
"stopwords": [
"www"
],
"ignore_case": true
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [
"my_char_filter",
"html_strip_char_filter"
],
"filter": [
"my_filter",
"uppercase"
],
"tokenizer": "my_tokenizer"
}
}
}
},
"mappings": {
"properties": {
"title":{
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
GET test_analyzer/_analyze
{
"analyzer": "my_analyzer",
"text": ["asd****a**sd,<a>www</a>.elastic!org?<p>cnelasticsearch</p><b><span>"]
}
PUT test_analyzer/_doc/1
{
"title":"asd****a**sd,<a>www</a>.elastic!org?<p>cnelasticsearch</p><b><span>"
}
8、analyzer ** search_analyzer
8.1 ********
- analyzer:******************,****************,******************,******
source data - search_analyzer:************,**********************,**********,****************。
- ** search_analyzer ********,********** analyzer,** analyzer ******,search_analyzer ** analyzer ********
standard
8.2 ********
PUT test_analyzer
{
"settings": {
"analysis": {
"tokenizer": {
"my_tokenizer": {
"type": "pattern",
"pattern": "[ ,.!?]"
},
"my_search_tokenizer": {
"type": "pattern",
"pattern": "[<>(){}]"
}
},
"char_filter": {
"html_strip_char_filter": {
"type": "html_strip",
"escaped_tags": [
"a"
]
},
"my_char_filter": {
"type": "mapping",
"mappings": [
"** => *",
"** => *",
"** => *"
]
}
},
"filter": {
"my_filter": {
"type": "stop",
"stopwords": [
"www"
],
"ignore_case": true
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [
"my_char_filter",
"html_strip_char_filter"
],
"filter": [
"my_filter"
],
"tokenizer": "my_tokenizer"
},
"my_search_analyzer": {
"type": "custom",
"char_filter": [
"my_char_filter",
"html_strip_char_filter"
],
"filter": [
"my_filter"
],
"tokenizer": "my_search_tokenizer"
}
}
}
},
"mappings": {
"properties": {
"title":{
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "my_search_analyzer"
}
}
}
}
GET test_analyzer/_analyze
{
"analyzer": "my_analyzer",
"text": ["asd****a**sd,<a>www</a>.elastic!org?<p>cnelasticsearch</p><b><span>"]
}
GET test_analyzer/_analyze
{
"analyzer": "my_search_analyzer",
"text": ["ASD****a**sd<<a>www</a>>elastic)org(<p>cnELASTICSEARCH</p><b><span>"]
}
PUT test_analyzer/_doc/1
{
"title":"asd****a**sd,<a>www</a>.elastic!org?<p>cnelasticsearch</p><b><span>"
}
GET test_analyzer/_search
{
"query": {
"match": {
"title": "ASD****a**sd<<a>www</a>>)(<p>cnELASTICSEARCH</p><b><span>"
}
}
}
9、************:Normalizers
9.1 ****
normalizer ** analyzer **********,******************,****************normalizer******************,******** normalizer **** tokenizer
**** normalizer ******** keyword ************,**************** keyword **************************,************************** normalizer
9.2 ********
- normalizer ******** keyword ****
- normalizer ********************
9.3 ****
PUT test_normalizer
{
"settings": {
"analysis": {
"normalizer": {
"my_normalizer": {
"filter": [
"lowercase"
]
}
},
"analyzer": {
"my_analyzer": {
"filter": [
"uppercase"
],
"tokenizer": "standard"
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "keyword",
"normalizer": "my_normalizer"
},
"content": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
PUT test_normalizer/_doc/1
{
"title":"ELASTIC Org cn",
"content":"ELASTIC Org cn"
}
GET test_normalizer/_search
{
"query": {
"match": {
"title": "ELASTIC"
}
}
}
GET test_normalizer/_search
{
"query": {
"match": {
"content": "ELASTIC"
}
}
}
10、**********
10.1 **********
10.1.1 ****
10.1.2 ****
- **************:cd {es-root-path}/plugins/ && mkdir ik
- ********************:{es-root-path}/plugins/ik
- ******** ES ****
10.2 ********
10.2.1 ************
-
IKAnalyzer.cfg.xml:IK************
-
******:main.dic
-
**********:stopword.dic,********************
-
********:
- quantifier.dic:********:**********
- suffix.dic:********:********
- surname.dic:********:******
- preposition:********:******
-
**********:********、******、**************。
10.2.2 ik ********** analyzer:
- ik_max_word:************************,********“******************”******“**************,********,****,****,**********,****,**,**,******,****,**,****,****”,********************,**** Term Query;
- ik_smart:******************,********“******************”******“**************,****”,**** Phrase ****。
10.2.3 ************
GET _analyze
{
"analyzer": "ik_max_word",
"text": ["******************"]
}
GET _analyze
{
"analyzer": "ik_smart",
"text": ["******************"]
}
GET _analyze
{
"analyzer": "ik_max_word",
"text": ["******************************G"]
}
PUT test_ik
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
PUT test_ik/_doc/1
{
"title":"******************,**************"
}
GET test_ik/_search
{
"query": {
"match": {
"title": "****"
}
}
}
10.3 ****************
10.3.1 ********
********:IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer ********</comment>
<!--******************************** -->
<entry key="ext_dict">custom/es_extend.dic;custom/es_buzzword.dic</entry>
<!--**************************************-->
<entry key="ext_stopwords"></entry>
<!--****************************** -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--************************************-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
- ****************** ik/config
- ********************
;****。
10.3.2 ******
- ****:********,************
- ****:************
- ****:****************************
10.4 ******************
10.4.1 ********
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer ********</comment>
<!--******************************** -->
<entry key="ext_dict">custom/es_extend.dic;custom/es_buzzword.dic</entry>
<!--**************************************-->
<entry key="ext_stopwords"></entry>
<!--****************************** -->
<entry key="remote_ext_dict">http://localhost:9081/api/hotWord?wordlib=1</entry>
<!--************************************-->
<entry key="remote_ext_stopwords">http://localhost:9081/api/hotWord?wordlib=0</entry>
</properties>
10.4.2 Java ****
@RestController
@RequestMapping(value = "/api")
public class ApiController {
@RequestMapping(value = "hotWord")
public void msbHotword(HttpServletResponse response, Integer wordlib) throws IOException {
File file = new File(wordlib == 1 ? "/Users/jiuchuan/Desktop/es_buzzword.dic" : "/Users/jiuchuan/Desktop/es_stopwords.dic");
FileInputStream fis = new FileInputStream(file);
byte[] buffer = new byte[(int) file.length()];
response.setContentType("text/plain;charset=utf-8");
response.setHeader("Last-Modified", String.valueOf(buffer.length));
response.setHeader("ETag", String.valueOf(buffer.length));
int offset = 0;
while (fis.read(buffer, offset, buffer.length - offset) != -1) {
}
OutputStream out = response.getOutputStream();
out.write(buffer);
out.flush();
fis.close();
}
}
10.4.3 ******
-
****:
- ********
- **********
- ******
-
****:
- ****************,**********************,************
- ********************************
- ************************
10.5 **** MySQL ************
10.5.1 ********
********:******
10.5.2 ************
1、**************
-
MySQL **************
-
************
2、************
**************:
java.sql.SQLNonTransientConnectionException: Could not create connection to database server.
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:526) ~[?:?]
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:513) ~[?:?]
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:505) ~[?:?]
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:479) ~[?:?]
at com.mysql.cj.jdbc.ConnectionImpl.connectOneTryOnly(ConnectionImpl.java:1779) ~[?:?]
at com.mysql.cj.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:1596) ~[?:?]
at com.mysql.cj.jdbc.ConnectionImpl.<init>(ConnectionImpl.java:633) ~[?:?]
at com.mysql.cj.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:347) ~[?:?]
at com.mysql.cj.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:219) ~[?:?]
at java.sql.DriverManager.getConnection(DriverManager.java:683) ~[java.sql:?]
at java.sql.DriverManager.getConnection(DriverManager.java:230) ~[java.sql:?]
at org.wltea.analyzer.dic.Dictionary.loadMySQLExtDict(Dictionary.java:468) ~[?:?]
at org.wltea.analyzer.dic.Dictionary.loadMainDict(Dictionary.java:407) ~[?:?]
at org.wltea.analyzer.dic.Dictionary.reLoadMainDict(Dictionary.java:659) ~[?:?]
at org.wltea.analyzer.dic.HotDict.run(HotDict.java:6) ~[?:?]
at java.lang.Thread.run(Thread.java:1589) ~[?:?]
Caused by: java.security.AccessControlException: access denied ("java.net.SocketPermission" "127.0.0.1:3306" "connect,resolve")
at java.security.AccessControlContext.checkPermission(AccessControlContext.java:485) ~[?:?]
at java.security.AccessController.checkPermission(AccessController.java:1068) ~[?:?]
at java.lang.SecurityManager.checkPermission(SecurityManager.java:411) ~[?:?]
at java.lang.SecurityManager.checkConnect(SecurityManager.java:914) ~[?:?]
at java.net.Socket.connect(Socket.java:661) ~[?:?]
at com.mysql.cj.core.io.StandardSocketFactory.connect(StandardSocketFactory.java:202) ~[?:?]
at com.mysql.cj.mysqla.io.MysqlaSocketConnection.connect(MysqlaSocketConnection.java:57) ~[?:?]
at com.mysql.cj.mysqla.MysqlaSession.connect(MysqlaSession.java:122) ~[?:?]
at com.mysql.cj.jdbc.ConnectionImpl.connectOneTryOnly(ConnectionImpl.java:1726) ~[?:?]
********:********************
SELECT User, Host FROM mysql.user;
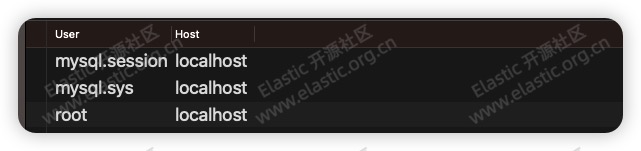
**** jdk **********,** jdk****/conf/security/java.policy**************:
grant {
permission java.lang.RuntimePermission "getClassLoader";
permission java.lang.RuntimePermission "createClassLoader";
permission java.lang.RuntimePermission "setContextClassLoader";
permission java.net.SocketPermission "127.0.0.1:3306","connect,resolve";
}
****************************,**********************************。
11、********
11.1 ****
- char filter ** token filter ********************,********************
11.2 ********
//****
PUT test_token_filter_synonym
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"filter": "my_synonym"
}
},
"filter": {
"my_synonym": {
"type": "synonym",
"synonyms_path": "analysis/synonym.txt"
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
//****
POST test_token_filter_synonym/_bulk
{"index":{}}
{"title":"a"}
{"index":{}}
{"title":"b"}
{"index":{}}
{"title":"c"}
{"index":{}}
{"title":"d"}
{"index":{}}
{"title":"s"}
{"index":{}}
{"title":"q"}
{"index":{}}
{"title":"w"}
{"index":{}}
{"title":"e"}
{"index":{}}
{"title":"r"}
{"index":{}}
{"title":"ss"}
GET test_token_filter_synonym/_analyze
{
"tokenizer": "standard",
"filter": ["my_synonym"],
"text": ["a"]
}
GET test_token_filter_synonym/_search
GET test_token_filter_synonym/_search
{
"query": {
"match": {
"title": "q"
}
}
}


