0.引言
elasticsearch支持各种类型的聚合查询,给我们做数据统计、数据分析时提供了强大的处理能力,但是作为java开发者,如何在java client中实现这些聚合呢?
我们知道spring-data-elasticsearch提供了针对整合spring的es java client,但是在elastic、spring-data官方文档中都没有详细说明聚合查询在java client中如何实现。
所以本期,我们的目标就是一篇将这些聚合操作一网打尽!
为了更好的将这些聚合讲解清楚,我们结合es官方文档的结构,将三种类型的聚合一一讲解。但不会将每种小类型都演示一遍,相信经过几种常用类型的演示,大家自己也能推敲出其他类型的用法。如果实在写不出来的可以留言博主,我们一起来探讨

1. 运行环境
本次演示基于以下环境
spring-data-elasticsearch3.2.12.RELEASE
基础环境的搭建可参考这篇文章:
从零搭建springboot+spring data elasticsearch3.x环境
在开始讲解之前,我们先声明我们的索引结构,方便大家后续理解我们的案例
# 订单索引,一个订单下有多个商品
PUT order_test
{
"mappings": {
"properties": {
// 订单状态 0未付款 1未发货 2运输中 3待签收 4已签收
"status": {
"type": "integer"
},
// 订单编号
"no": {
"type": "keyword"
},
// 下单时间
"create_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
// 订单金额
"amount": {
"type": "double"
},
// 创建人
"creator":{
"type": "keyword"
},
// 商品信息
"product":{
"type": "nested",
"properties": {
// 商品ID
"id": {
"type": "keyword"
},
// 商品名称
"name":{
"type": "keyword"
},
// 商品价格
"price": {
"type": "double"
},
// 商品数量
"quantity": {
"type": "integer"
}
}
}
}
}
}
测试数据,供大家跟练
POST order_test/_bulk
{"index":{}}
{"status":0,"no":"DD202205280001","create_time":"2022-05-01 12:00:00","amount":100.0,"creator":"张三","product":[{"id":"1","name":"苹果","price":20.0,"quantity":5}]}
{"index":{}}
{"status":0,"no":"DD202205280002","create_time":"2022-05-01 12:00:00","amount":100.0,"creator":"李四","product":[{"id":"2","name":"香蕉","price":20.0,"quantity":5}]}
{"index":{}}
{"status":1,"no":"DD202205280003","create_time":"2022-05-02 12:00:00","amount":100.0,"creator":"张三","product":[{"id":"2","name":"香蕉","price":20.0,"quantity":5}]}
{"index":{}}
{"status":2,"no":"DD202205280004","create_time":"2022-05-01 12:00:00","amount":150.0,"creator":"王二","product":[{"id":"1","name":"苹果","price":30.0,"quantity":5}]}
{"index":{}}
{"status":2,"no":"DD202205280005","create_time":"2022-05-03 12:00:00","amount":100.0,"creator":"55555","product":[{"id":"2","name":"香蕉","price":20.0,"quantity":5}]}
{"index":{}}
{"status":3,"no":"DD202205280006","create_time":"2022-05-04 12:00:00","amount":150.0,"creator":"李四","product":[{"id":"3","name":"榴莲","price":150.0,"quantity":1}]}
{"index":{}}
{"status":4,"no":"DD202205280007","create_time":"2022-05-04 12:00:00","amount":100.0,"creator":"张三","product":[{"id":"2","name":"香蕉","price":20.0,"quantity":5}]}
{"index":{}}
{"status":3,"no":"DD202205280008","create_time":"2022-05-01 12:00:00","amount":200.0,"creator":"王二","product":[{"id":"1","name":"苹果","price":40.0,"quantity":5}]}
{"index":{}}
{"status":4,"no":"DD202205280009","create_time":"2022-05-03 12:00:00","amount":100.0,"creator":"55555","product":[{"id":"2","name":"香蕉","price":20.0,"quantity":5}]}
2. 分桶聚合 Bucket aggregations
2.1 Terms aggregation
分桶聚合中最常用的就是terms聚合了,它可以按照指定字段将数据分组聚合,类似mysql中的group by
- 案例
要求统计各种状态的单数
- DSL
GET order_test/_search
{
"size": 0,
"aggs": {
"status_bucket": {
"terms": {
"field": "status"
}
}
}
}
- 执行结果

- java实现
public void termsAgg(){
String aggName = "status_bucket";
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
queryBuilder.withPageable(PageRequest.of(0,1));
TermsAggregationBuilder termsAgg = AggregationBuilders.terms(aggName).field("status");
queryBuilder.addAggregation(termsAgg);
Aggregations aggregations = restTemplate.query(queryBuilder.build(), SearchResponse::getAggregations);
Terms terms = aggregations.get(aggName);
List<? extends Terms.Bucket> buckets = terms.getBuckets();
HashMap<String,Long> statusRes = new HashMap<>();
buckets.forEach(bucket -> {
statusRes.put(bucket.getKeyAsString(),bucket.getDocCount());
});
System.out.println("---聚合结果---");
System.out.println(statusRes);
}
2.2 Date histogram aggregation
日期分组聚合可以按照日期进行分组,常用到一些日期趋势统计中
- 案例
统计每天的下单量
- DSL
GET order_test/_search
{
"size": 0,
"aggs": {
"date": {
"date_histogram": {
"field": "create_time",
"calendar_interval": "day",
"format": "yyyy-MM-dd"
}
}
}
}
- 执行结果
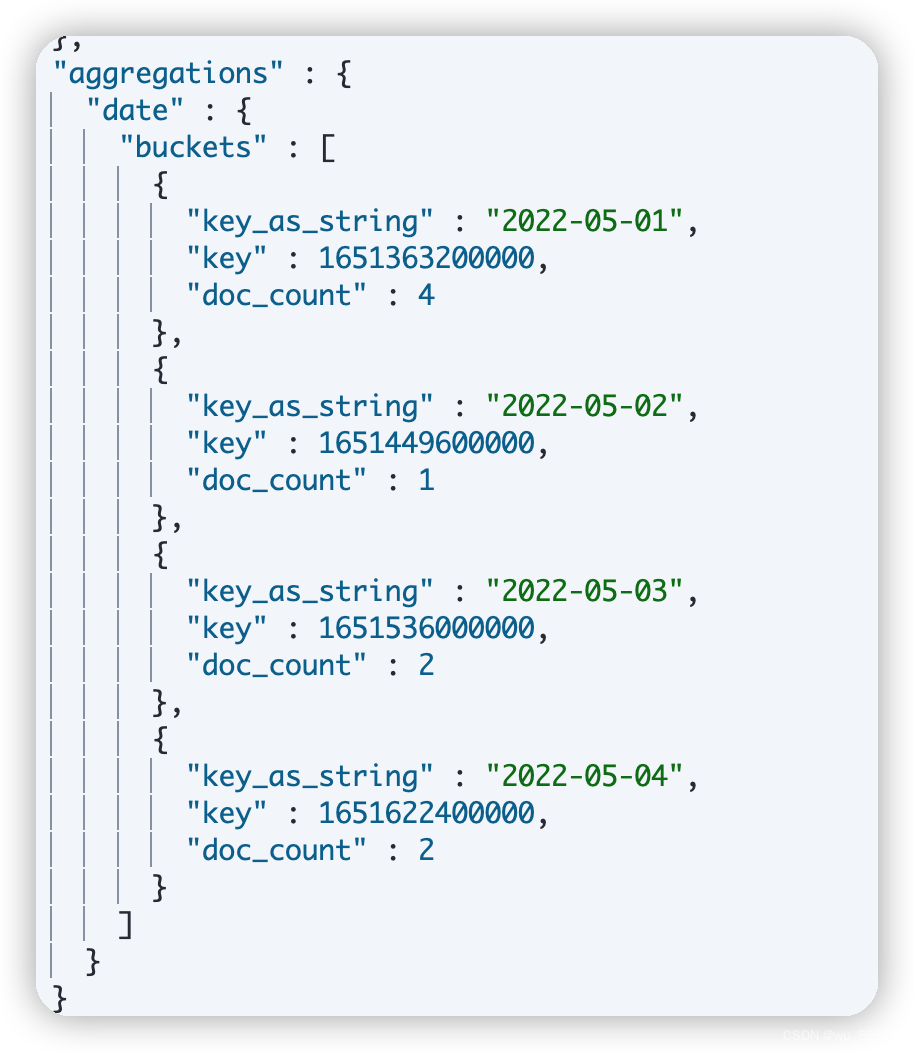
- java
public void dateHistogramAgg(){
String aggName = "date";
DateHistogramAggregationBuilder dateHistogramAggregation = AggregationBuilders.dateHistogram(aggName).field("create_time")
.calendarInterval(DateHistogramInterval.days(1)).format("yyyy-MM-dd");
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
queryBuilder.withPageable(PageRequest.of(0,1)).addAggregation(dateHistogramAggregation);
Aggregations aggregations = restTemplate.query(queryBuilder.build(), SearchResponse::getAggregations);
ParsedDateHistogram terms = aggregations.get(aggName);
List<? extends Histogram.Bucket> buckets = terms.getBuckets();
HashMap<String,Long> resultMap = new HashMap<>();
buckets.forEach(bucket -> {
resultMap.put(bucket.getKeyAsString(),bucket.getDocCount());
});
System.out.println("---聚合结果---");
System.out.println(resultMap);
}
拓展:
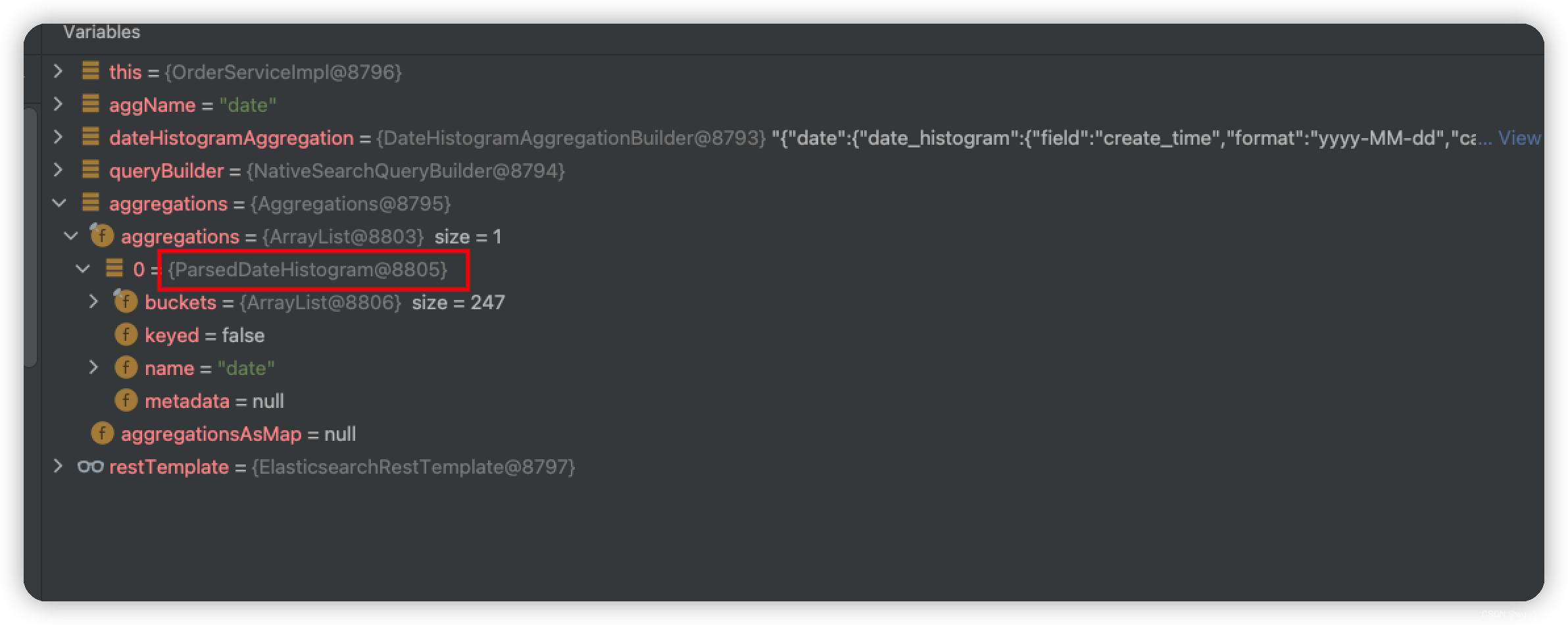
这里大家会发现使用的是ParsedDateHistogram来承接结果,与上述的Term不一致,那么我们怎么知道什么时候该用哪个呢?实际上可以通过断点来判断
我们通过把断点截取到restTemplate.query的执行结果aggregations之后,会发现该aggregations中的元素已经标明了其类型为ParsedDateHistogram,所以大家只需要跟着用就可以了。
2.3 Range aggregation
范围分组聚合可以帮助我们按照指定的数值范围进行分组
- 案例
统计订单金额在0~100,100~200,200+ 这几个区间的订单数量
- DSL
GET order_test/_search
{
"size": 0,
"aggs": {
"date_range": {
"range": {
"field": "amount",
"ranges": [
{
"to": "100"
},
{
"from": "100",
"to": "200"
},
{
"from": "200"
}
]
}
}
}
}
- 执行结果

- java
public void rangeAgg(){
String aggName = "range";
RangeAggregationBuilder agg = AggregationBuilders.range(aggName).field("amount").addUnboundedTo(100).addRange(100, 200).addUnboundedFrom(200);
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
queryBuilder.withPageable(PageRequest.of(0,1)).addAggregation(agg);
Aggregations aggregations = restTemplate.query(queryBuilder.build(), SearchResponse::getAggregations);
ParsedRange terms = aggregations.get(aggName);
List<? extends Range.Bucket> buckets = terms.getBuckets();
HashMap<String,Long> resultMap = new HashMap<>();
buckets.forEach(bucket -> {
resultMap.put(bucket.getKeyAsString(),bucket.getDocCount());
});
System.out.println("---聚合结果---");
System.out.println(resultMap);
}
2.4 Nested aggregation
nested聚合专用于json型子对象进行聚合,比如上述案例中product是json型数组,如果当我们想通过商品中的属性来聚合统计时就需要用到nested聚合,直接使用product.name来聚合其结果则不会是我们预期的,这主要与es针对数组的存储形式有关。
- 案例
统计每种货物的订单数
- DSL
GET order_test/_search
{
"size": 0,
"aggs": {
"product_nested": {
"nested": {
"path": "product"
},
"aggs": {
"name_bucket": {
"terms": {
"field": "product.name"
}
}
}
}
}
}
- 执行结果

- java:这里我们涉及到要设置一个嵌套聚合,可以通过
subAggregation方法来定义子聚合
public void nestedAgg(){
String aggName = "product_nested";
String termsAggName = "name_bucket";
NestedAggregationBuilder aggregationBuilder = AggregationBuilders.nested(aggName, "product").subAggregation(AggregationBuilders.terms(termsAggName).field("product.name"));
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder()
.withPageable(PageRequest.of(0,1))
.addAggregation(aggregationBuilder);
Aggregations aggregations = restTemplate.query(queryBuilder.build(), SearchResponse::getAggregations);
ParsedNested nestedRes = aggregations.get(aggName);
Terms terms = nestedRes.getAggregations().get(termsAggName);
List<? extends Terms.Bucket> buckets = terms.getBuckets();
HashMap<String,Long> resMap = new HashMap<>();
buckets.forEach(bucket -> {
resMap.put(bucket.getKeyAsString(),bucket.getDocCount());
});
System.out.println("---聚合结果---");
System.out.println(resMap);
}
3. 数值聚合 Metrics aggregations
3.1 Sum aggregations
求和聚合是常用的聚合之一,经常与分组聚合配合使用,用来统计出各组下的合计
- 案例
求5月1日销售总额
- DSL:这里我们添加了一个query语句,用来限定聚合范围是5.1日的订单
GET order_test/_search
{
"query": {
"range": {
"create_time": {
"format": "yyyy-MM-dd",
"from": "2022-05-01",
"to": "2022-05-01"
}
}
},
"size": 0,
"aggs": {
"sum_amount": {
"sum": {
"field": "amount"
}
}
}
}
- 执行结果

- java
public void sumAgg(){
String aggName = "sumAmount";
SumAggregationBuilder agg = AggregationBuilders.sum(aggName).field("amount");
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder()
.withPageable(PageRequest.of(0,1))
.withQuery(QueryBuilders.rangeQuery("create_time").format("yyyy-MM-dd").from("2022-05-01").to("2022-05-01"))
.addAggregation(agg);
Aggregations aggregations = restTemplate.query(queryBuilder.build(), SearchResponse::getAggregations);
ParsedSum metric = aggregations.get(aggName);
double value = metric.getValue();
System.out.println("---聚合结果---");
System.out.println(value);
}
3.2 Script aggregation
脚本聚合支持我们通过脚本语言来自定义聚合的数值,es中脚本默认的语言为painless。需要注意的是脚本语法非常影响性能,我们一般是尽量避免使用。同时es中还提供了专门的脚本数值聚合 script metric aggregation,但因为不太常用,所以我们这里以更加常用的聚合脚本来讲解
- 案例
求所有货物平均单价
- DSL:注意这里不能直接用product.price。因为product是数组,里面可能包含多种货物,所以应该用订单总金额除以所有订单的货物数量
GET order_test/_search
{
"size": 0,
"aggs": {
"total_amount":{
"sum": {
"field": "amount"
}
},
"total_quantity":{
"sum": {
"script": {
"source": """
int total = 0;
for(int i=0; i<params._source['product'].size(); i++){
if(params._source['product'][i]['quantity'] != null){
total += params._source['product'][i]['quantity'];
}
}
return total;
"""
}
}
}
}
}
可以看到这里,原本sum聚合中是field属性的,改成了script脚本来动态计算属性值,从而实现聚合。同理,script脚本不仅可以使用到sum聚合中,也可以用到其他metric聚合中。
-
执行结果

将结果total_amount除以total_quantity即可得到平均价格 -
java
public void scriptAgg(){
String totalAmountAggName = "total_amount";
String totalQuantityAggName = "total_quantity";
SumAggregationBuilder amountAgg = AggregationBuilders.sum(totalAmountAggName).field("amount");
SumAggregationBuilder quantityAgg = AggregationBuilders.sum(totalQuantityAggName).script(
new Script("int total = 0;\n" +
" for(int i=0; i<params._source['product'].size(); i++){\n" +
" if(params._source['product'][i]['quantity'] != null){\n" +
" total += params._source['product'][i]['quantity'];\n" +
" }\n" +
" }\n" +
" return total;"));
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder()
.withPageable(PageRequest.of(0,1))
.addAggregation(amountAgg).addAggregation(quantityAgg);
Aggregations aggregations = restTemplate.query(queryBuilder.build(), SearchResponse::getAggregations);
ParsedSum amountRes = aggregations.get(totalAmountAggName);
ParsedSum quantityRes = aggregations.get(totalQuantityAggName);
double avgPrice = amountRes.getValue()/quantityRes.getValue();
System.out.println("---聚合结果---");
System.out.println(avgPrice);
}
4. 管道聚合 Pipeline aggregations
首先要理解管道聚合的概念,与其他聚合不同,管道聚合是在其他聚合的结果下进行聚合操作的,所以管道聚合是配合其他聚合来工作的,而不是像其他聚合那样直接操作文档数据。
4.1 Bucket script aggregation
分桶脚本聚合用于多分桶聚合的指标进行二次计算,我们通过案例来具体体会他的用法。
- 案例
求每个订单的货物平均单价
- DSL:我们上述求解过所有订单的货物平均单价,这里需要求解每个订单的货物平均单价,那么就需要先对数据按照订单进行分桶
GET order_test/_search
{
"size": 0,
"aggs": {
"order_bucket": {
"terms": {
"field": "no"
},
"aggs": {
"total_amount": {
"sum": {
"field": "amount"
}
},
"total_quantity": {
"sum": {
"script": {
"source": """
int total = 0;
for(int i=0; i<params._source['product'].size(); i++){
if(params._source['product'][i]['quantity'] != null){
total += params._source['product'][i]['quantity'];
}
}
return total;
"""
}
}
},
"avg_price": {
"bucket_script": {
"buckets_path": {
"amount": "total_amount",
"quantity": "total_quantity"
},
"script": "params.amount / params.quantity"
}
}
}
}
}
}
- 执行结果
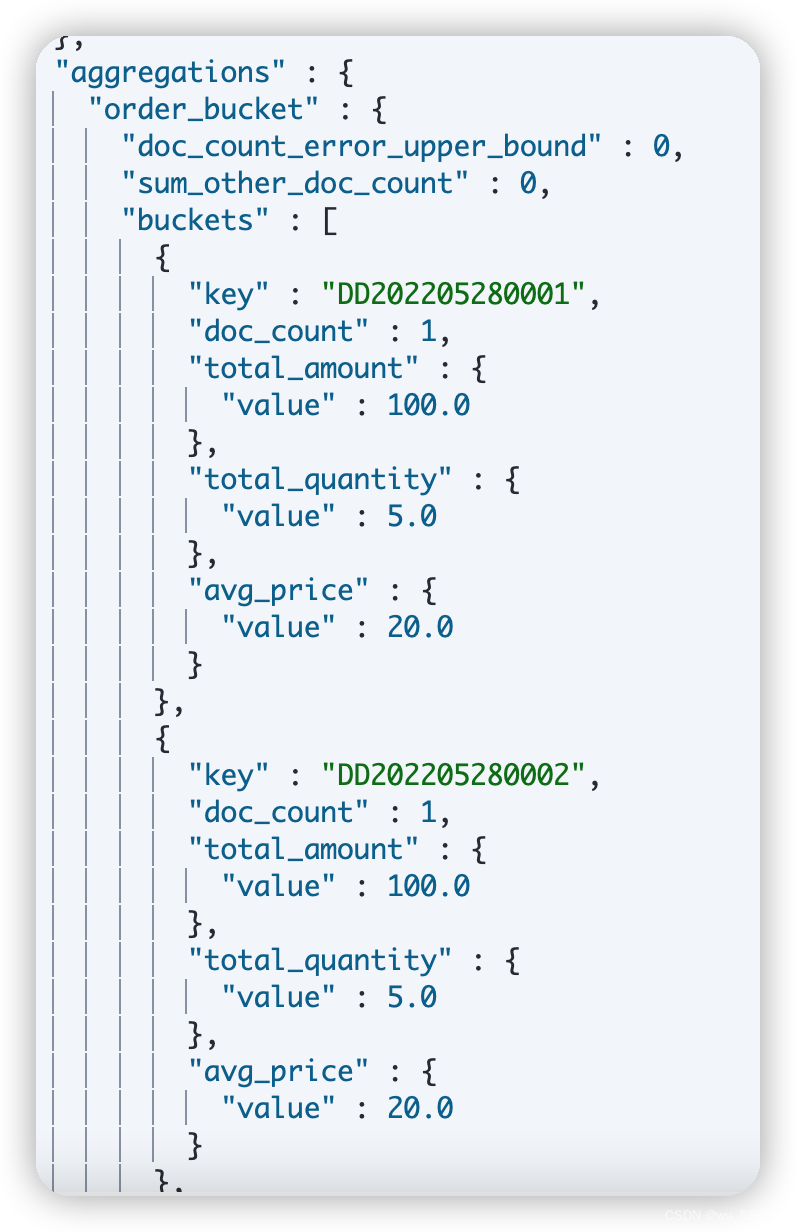
- java:需要注意的是管道聚合使用的聚合生成器就不再是
AggregationBuilders类,而是PipelineAggregatorBuilders,其余的用法类似
public void bucketScriptAgg(){
String aggName = "order_bucket";
String totalAmountAggName = "total_amount";
String totalQuantityAggName = "total_quantity";
String avgPriceAggName = "avg_price";
HashMap<String,String> bucketsPath = new HashMap<>();
bucketsPath.put("amount","total_amount");
bucketsPath.put("quantity","total_quantity");
TermsAggregationBuilder aggregationBuilder = AggregationBuilders.terms(aggName).field("no")
.subAggregation(AggregationBuilders.sum(totalAmountAggName).field("amount"))
.subAggregation(AggregationBuilders.sum(totalQuantityAggName).script(
new Script("int total = 0;\n" +
" for(int i=0; i<params._source['product'].size(); i++){\n" +
" if(params._source['product'][i]['quantity'] != null){\n" +
" total += params._source['product'][i]['quantity'];\n" +
" }\n" +
" }\n" +
" return total;")
))
.subAggregation(PipelineAggregatorBuilders.bucketScript(avgPriceAggName, bucketsPath,
new Script("params.amount / params.quantity")));
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder()
.withPageable(PageRequest.of(0,1))
.addAggregation(aggregationBuilder);
Aggregations aggregations = restTemplate.query(queryBuilder.build(), SearchResponse::getAggregations);
HashMap<String,Double> resultMap = new HashMap<>();
Terms terms = aggregations.get(aggName);
List<? extends Terms.Bucket> buckets = terms.getBuckets();
buckets.forEach(bucket -> {
ParsedSimpleValue avgRes = bucket.getAggregations().get(avgPriceAggName);
resultMap.put(bucket.getKeyAsString(),Double.parseDouble(avgRes.getValueAsString()));
});
System.out.println("---聚合结果---");
System.out.println(resultMap);
}
4.2 Bucket sort aggregation
bucket sort可以针对聚合结果实现自定义排序、分页,在桶排序中很常用。如果对于该聚合不清楚的同学可以查看我往篇博客介绍
- 案例
求订单货物平均单价TOP5的订单
- DSL:上述题目不仅要求我们订单的货物平均单价,还要根据平均单价排序,且分页取前5
GET order_test/_search
{
"size": 0,
"aggs": {
"order_bucket": {
"terms": {
"field": "no"
},
"aggs": {
"total_amount": {
"sum": {
"field": "amount"
}
},
"total_quantity": {
"sum": {
"script": {
"source": """
int total = 0;
for(int i=0; i<params._source['product'].size(); i++){
if(params._source['product'][i]['quantity'] != null){
total += params._source['product'][i]['quantity'];
}
}
return total;
"""
}
}
},
"avg_price": {
"bucket_script": {
"buckets_path": {
"amount": "total_amount",
"quantity": "total_quantity"
},
"script": "params.amount / params.quantity"
}
},
"avg_price_sort": {
"bucket_sort": {
"sort": [
{"avg_price":{"order":"desc"}}
],
"from": 0,
"size": 5
}
}
}
}
}
}
-
执行结果
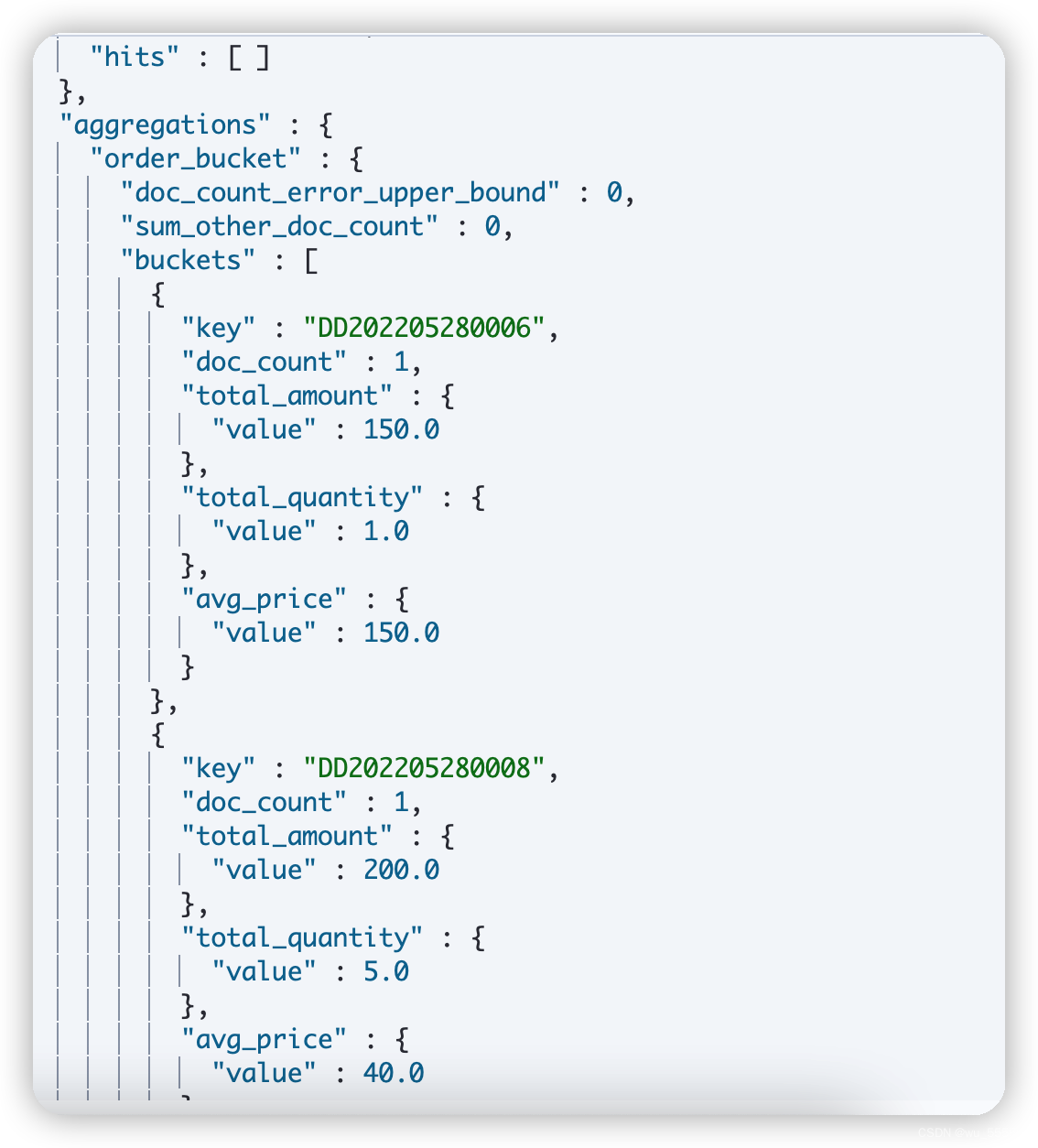
-
java:同上使用的聚合生成器就不再是
AggregationBuilders类,而是PipelineAggregatorBuilders,其余的用法类似
public void bucketSortAgg(){
String aggName = "order_bucket";
String totalAmountAggName = "total_amount";
String totalQuantityAggName = "total_quantity";
String avgPriceAggName = "avg_price";
String bucketSortAggName = "avg_price_sort";
HashMap<String,String> bucketsPath = new HashMap<>();
bucketsPath.put("amount","total_amount");
bucketsPath.put("quantity","total_quantity");
List<FieldSortBuilder> sortList = new ArrayList<>();
FieldSortBuilder fieldSortBuilder = new FieldSortBuilder("avg_price").order(SortOrder.DESC);
sortList.add(fieldSortBuilder);
TermsAggregationBuilder aggregationBuilder = AggregationBuilders.terms(aggName).field("no")
.subAggregation(AggregationBuilders.sum(totalAmountAggName).field("amount"))
.subAggregation(AggregationBuilders.sum(totalQuantityAggName).script(
new Script("int total = 0;\n" +
" for(int i=0; i<params._source['product'].size(); i++){\n" +
" if(params._source['product'][i]['quantity'] != null){\n" +
" total += params._source['product'][i]['quantity'];\n" +
" }\n" +
" }\n" +
" return total;")
))
.subAggregation(PipelineAggregatorBuilders.bucketScript(avgPriceAggName, bucketsPath,
new Script("params.amount / params.quantity")))
.subAggregation(PipelineAggregatorBuilders.bucketSort(bucketSortAggName,sortList).from(0).size(5));
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder()
.withPageable(PageRequest.of(0,1))
.addAggregation(aggregationBuilder);
Aggregations aggregations = restTemplate.query(queryBuilder.build(), SearchResponse::getAggregations);
// 因为要求按序输出,所以这里使用LinkedHashMap,HashMap不会按照顺序显示
LinkedHashMap<String,Double> resultMap = new LinkedHashMap<>();
Terms terms = aggregations.get(aggName);
List<? extends Terms.Bucket> buckets = terms.getBuckets();
buckets.forEach(bucket -> {
ParsedSimpleValue avgRes = bucket.getAggregations().get(avgPriceAggName);
resultMap.put(bucket.getKeyAsString(),Double.parseDouble(avgRes.getValueAsString()));
});
System.out.println("---聚合结果---");
System.out.println(resultMap);
}
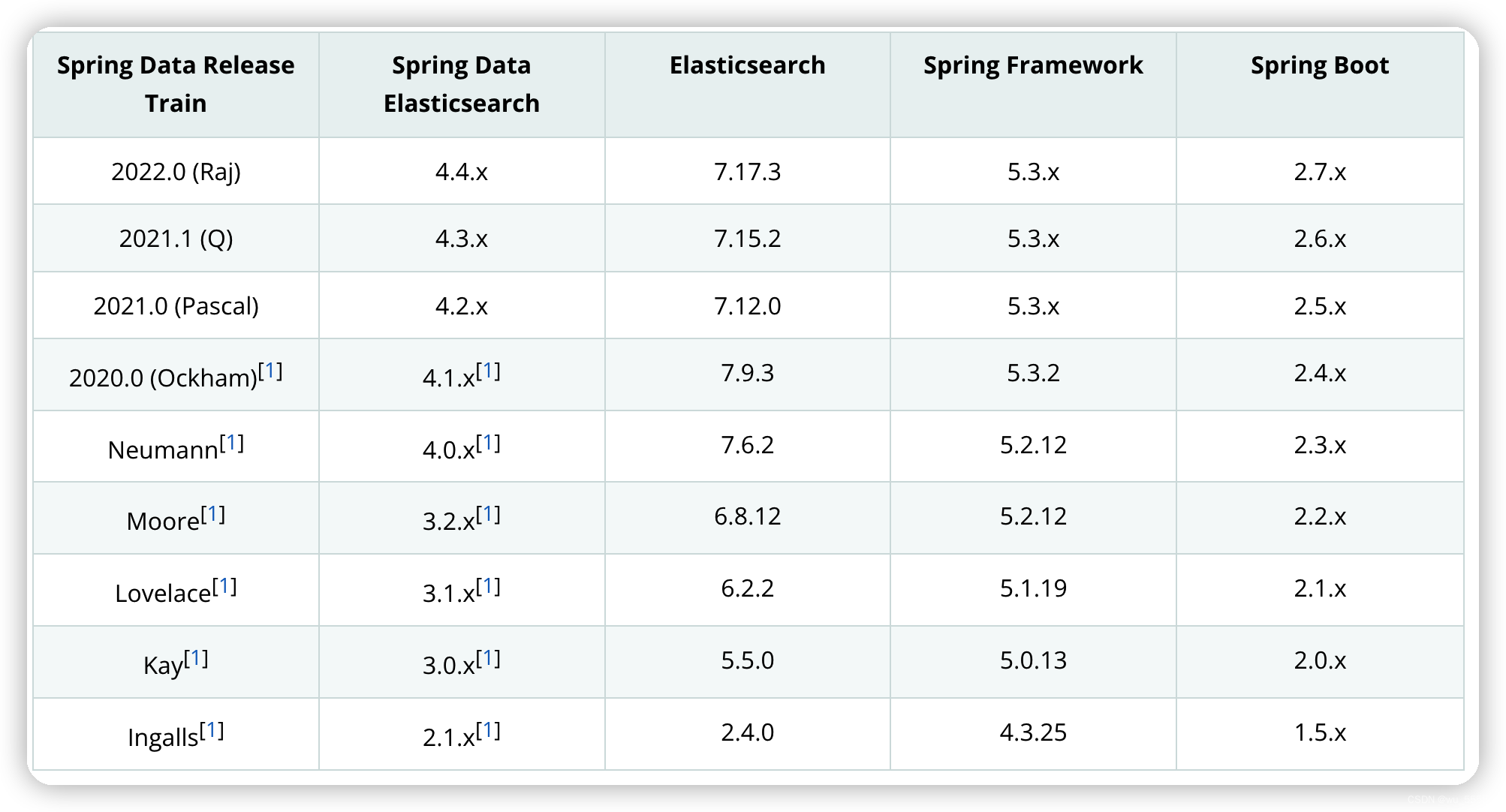
需要注意的是并不是所有的DSL都可以在spring-data-elasticsearch中实现,某些操作在kibana中可以执行,但是在spring-data-elasticsearch中就不能执行了,还要注意es版本与spring-data-elasticsearch的版本统一,具体如下图
要想对java client深入理解,更多需要大家自己动手操作试试
关注公众号 Elastic之家,了解更多新鲜内容

原文地址:https://wu55555.blog.csdn.net/article/details/125013357

